
My general motivation for writing about AI topics is to bring a little more attention and awareness to AI in the environment that I call "home" which is crypto, STEEM, CT and some corners of InfoSec.
To me many of these fields, together with AI have the potential for some interesting convergence or actually are already heavily intersected.
I was motivated to write something after viewing "Nuts and Bolts of Applying Deep Learning (Andrew Ng)" share by Lex Friedman.
Lex shares some great talks on very interesting AI topics, in this case it's about deep learning.
So what does it even mean, "Deep Learning"?
Let my try to put it this way... deep learning breakthroughs drive the AI boom of the recent past!
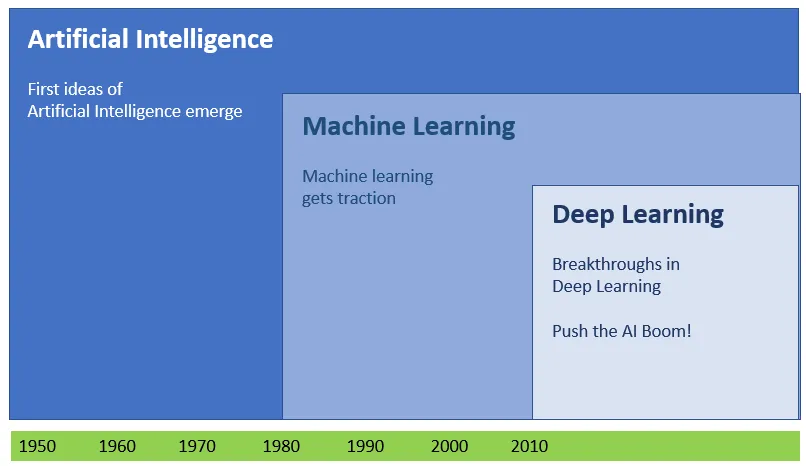
When first papers on AI were published, beginning in the early 1950ties the optimism that went along with this died down a little by recurring failures over the following decades.
These sobering flops were in many cases bound to missing capabilities and missing performance of IT systems available at that time. In the 1980ties machine learning got some traction and certain fields were proofing grounds for AI like first attempts at pattern recognition with voice recognition for example.
I remember very good the different voice recognition tools I tried or even have thoroughly tested in the 90ties. I remember that some of my customers (lawyers, md's and executives) seriously thought about using voice recognition instead of the good old tape recorder and buying/paying for typing support.
I also remember that these efforts, even after many hours invested into training/retraining of the voice recognition engines by the individuals that tried to use this, weren't rewarded as expected.
The results always seemed to stay kind of patchy and a lot of editing/correcting work had to be done after a text was "spoken" into a voice recognition application. Things looked a little better when it came to simpler voice recognition usage like for instance a limited set of voice commands that were trained into the regarding voice recognition engine but this of course could not be compared to free text in a complex language not to mention issues with different dialects in one language for example.
Voice recognition could only be as good as the training part of such an application was complex and always bound to a dedicated user with his voice and dialect and the context limitation voice recognition would be used is (specific grammar for specific needs).
Things could get very messy if the user had an cold for instance and the saved "voice patterns" for the to recognize words sounded different and could not be matched.
It all had a clumsy and awkward touch to it and not much of this seemed to justify the use of the word intelligence that's part of AI.
Why have I chosen voice recognition as a base for some examples and personal experiences in regards to AI development and AI improvement over the last 3-5 decades?
Well, I chose this because voice recognition much like the manipulation of the physical world shows impressively the limitations of AI development over time.
Where AI has proven to be very efficient with stunning results is when an AI algorithm is fed with large amounts of data to perform analytics for instance.
But our voice recognition example here, when looked at closely, shows quite some deep complexity and many challenges to get this right.
The improvements of the last decade in this field, driven by deep learning, do actually show in reduced training time and higher off the bat accuracy!
If you played around with this for some time, like with translation apps (google translate) for instance, you surely have recognized the sudden jump in quality and efficiency in the last decade like I did.
Check out: https://cloud.google.com/speech-to-text/ for instance. You'll be surprised with how much less training this AI driven Voice to text solution delivers acceptable results I guess.
This article here gives a pretty good insight into the status of speech recognition solutions: https://emerj.com/ai-sector-overviews/ai-for-speech-recognition/
Of course all these personal voice assistant solutions, that I see very critical because of the potential for privacy loss (privacy losses that have shown over and over with these solutions and the companies that make money with them), show very clearly this sped up progress in voice recognition in the last 5-10 years.
Back to our headline... so what does the "deep learning" approach come down to?
It seems it's sheer computing power! The more NN's (Neural Nets) the better, faster, more accurate deep learning can tackle problems thrown at it.
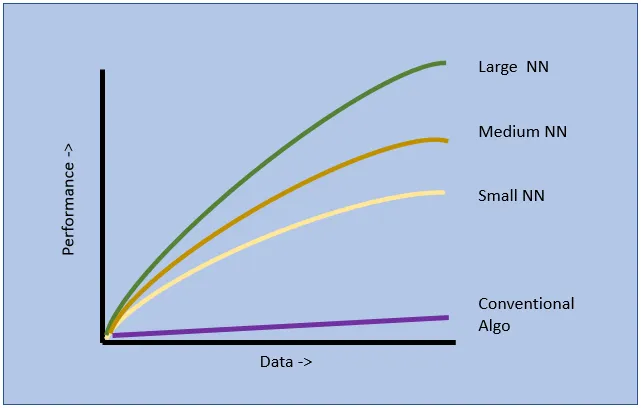
As Andrew Ng explains in this video, many problems that were thrown at machine learning conventional algorithms just seemed not be be able to handle the sheer amount of data they needed to process.
With the rise of the internet usage, mobile and IoT devices the use of Neural Networks became a common and with these NN's it was all about computing power. Only the large NN's are capable to deep dive into a large data set with acceptable performance.
What do you need to qualify to the upper right corner in this little pic. Well, you need a large and highly trained Neural Network and an large amount of data!
As you can probably spot with ease not for every problem there are large amounts of data you could use to train a large Neural Network.
As I'm writing this it becomes clear that certain terms and conditions that are used here might very well break through the "normie" barrier a lot! I'll try to get to the essence of deep learning while explaining one or the other buzz word, tech or architecture.
What's the difference between an traditional algorithm and an neural network?
You can look at this as an static logic using a set of rules and calculations that process data = tradtional vs. "self programming", adjusting on the fly and possibly using images, pictures, concepts as input data = Neural Networks.
Neural Networks also rely on massive parallel computing capabilities so that many things can be done in parallel while in contrast conventional algorithms may seem to do somethings in parallel while they are really sequentially tackling one task after the other.
Check out this little definition of "traditional computing" vs. "Neural Networks" from Stanford University.
Andrew Ng sketches out the general trends he's seeing in AI DL (deep learning).
"Size matters" = Skale... (Trend #1) Like I showed above the sheer parallel computing power to master working through large quantities of data.
Structuring of DL approaches into different "buckets" of algorithms
a.) General DL
b.) sequence models
c.) image/Picture processing
d.) unsupervised deep learning
End to End Deep learning (Trend #2)
As of now many of the DL results would be numbers (real numbers/integers). Kind of an simple output.
movie review -> sentiment 0/1 (positive/negative)
image -> object (numbers from 1-1000 for example)
The trend you can see forming is that DL approaches can output much more complex things. So for example not only detecting an object or something in an image but also putting this into context.
image -> caption
audio -> text transcript (voice to text)
english -> french (translation)
parameters -> image (synthesize a brand new image)
Especially this last part had really an transformative impact on AI development in general. From single numbers output to rich results/complex results.
What is absolutely clear is the fact that those with the most amount if data will continue to dominate the AI marketplace in the foreseeable future!
It really comes down to this! You can be as smart as you want but if you can't get your hands on sufficient amounts of data you will not be able to train a neural network for deep learning problem solutions, it's as simple as that!
Who has the most data at the tip of their hands?
Well, you guessed right, it's the existing global internet giants like google, Amazon, ebay, alibaba and so on.
Please check out Andrew Ng's talk about "The nuts and bolts of Deep Learning".

Please also check out the video description on youtube were Lex Friedman shares some further resources on AI and especially Deep Learning.
So much for my little 2 sats on this topic.
- What do you think about this?
- Should this be accepted as the imperative that only the big guns have a shot at the AI development front?
- Isn't it true that these internet giants have been accumulating this data without most of the people that provided this data even understanding that their online lives are constantly utilized and monetized?
Let me know what you think about this down in the comments!
Cheers!
Lucky