前言
我的文章主要以英文为主,为了支持和参与CN标签,我会把自己写的有关于人工智能相关的文章以中文刊载,还请各位支持。(此文章只会贴在CN标签,以免文章重叠)
由于上一篇文章在CN的反应实在太好,这次会反其道而行,率先在CN刊登文章,并于今天晚上发布英文版。谢谢CN各位的支持。
正文
虽然到2020年东京奥运还有三年时间,但日本正在努力准备这次盛会。其中一个大计就是雇用一个编程自驾车的团队。 日本自动化汽车公司ZMP已经宣布与东京的出租车公司Hinomaru Kotsu合作开发机械出租车。 ZMP近年来一直在开发自己的自动驾驶技术,包括硬件和软件。
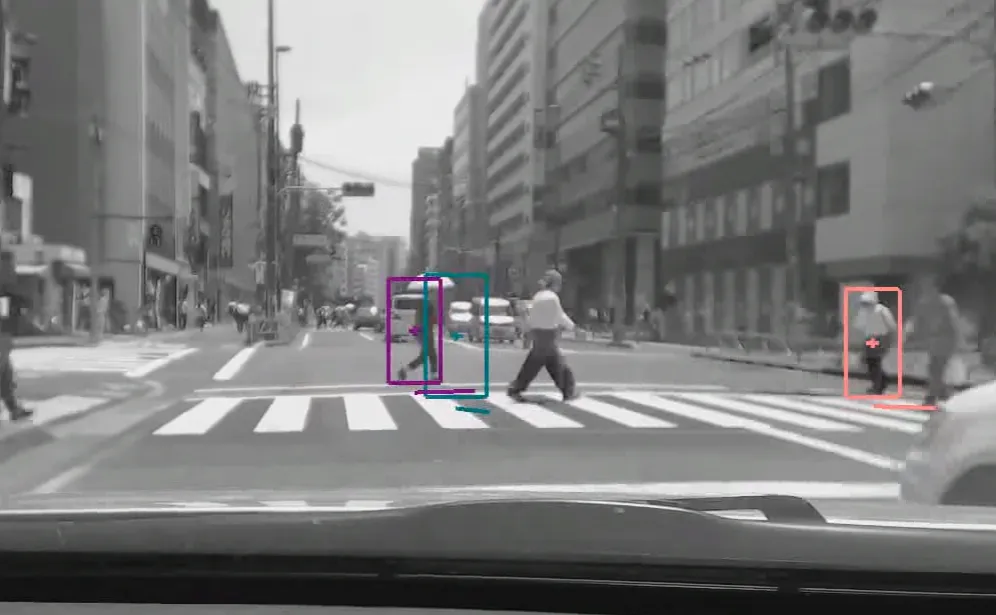
自去年以来,ZMP已经在街道上测试其自动驾驶技术,研究将适用于出租车。消息人士说,出租车将作为东京的旅客使用作为交通工具。公司目前仍在以驾驶人员的方式进行监控,希望能在今年年底之前实现无人驾驶员自动驾驶。

背后的技术
虽然公司永远不会透露他们使用的软件,但我认为,他们必须通过PyTorch,Caffe2或Tensorflow构建自驾驾驶软件。这些都是现在最流行的深入学习工具库,使程序员能够执行类似的机器学习算法。
今天我想通过使用Tensorflow展示这个技术。
TensorFlow的物件检测API
如果您是专业程序员,请查看
Official blog from Google: https://research.googleblog.com/2017/06/supercharge-your-computer-vision-models.html
Code: https://github.com/tensorflow/models/blob/master/object_detection/object_detection_tutorial.ipynb
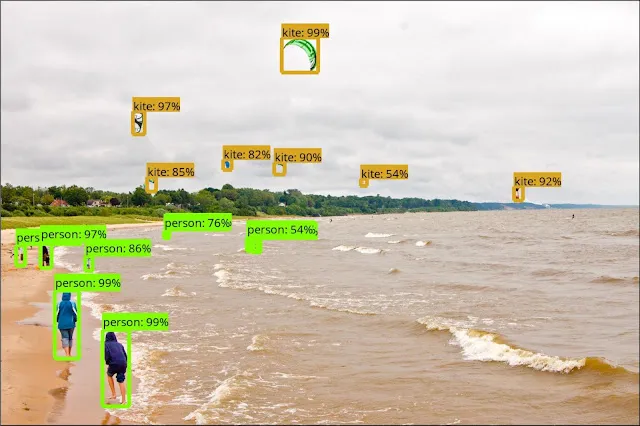
其实一直以来,自驾驾驶并不是问题,即使没有深入学习或机器学习,自驾驾驶技术也可以非常成熟。真正的问题是在对象检测,例如行人和交通灯
现在有几种最先进的技术,我们可以使用。这里是2017年最受欢迎的检测模型。
- Single Shot Multibox Detector (SSD) with MobileNets
- SSD with Inception V2
- Region-Based Fully Convolutional Networks (R-FCN) with Resnet 101
- Faster RCNN with Resnet 101
- Faster RCNN with Inception Resnet v2
简单解释背后的技术
首先,您需要了解,图像处理任务一般来说有四种类型
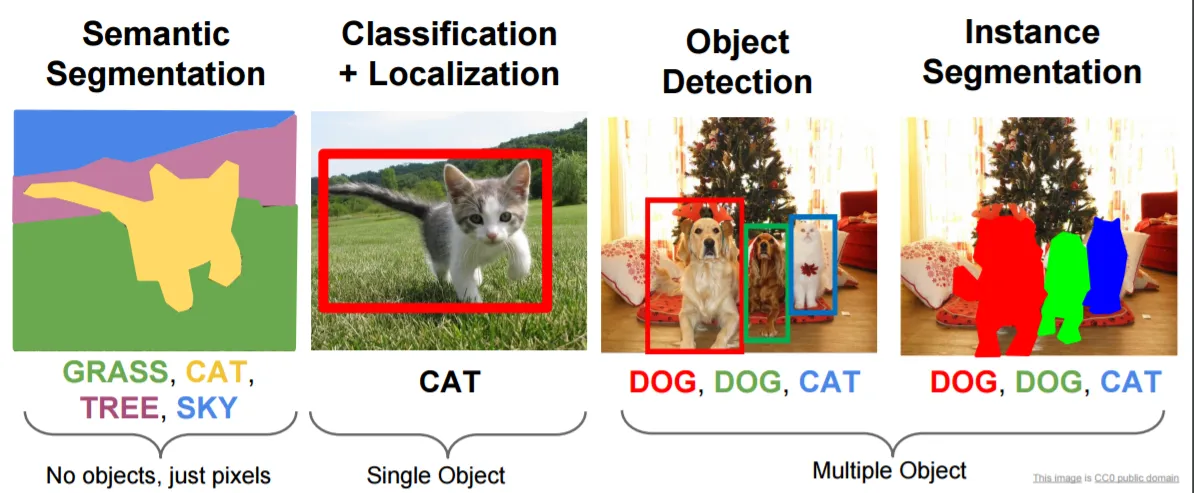
我们现在专注于第二个“分类+本地化(即在图象中划出行人在图中的位置)”
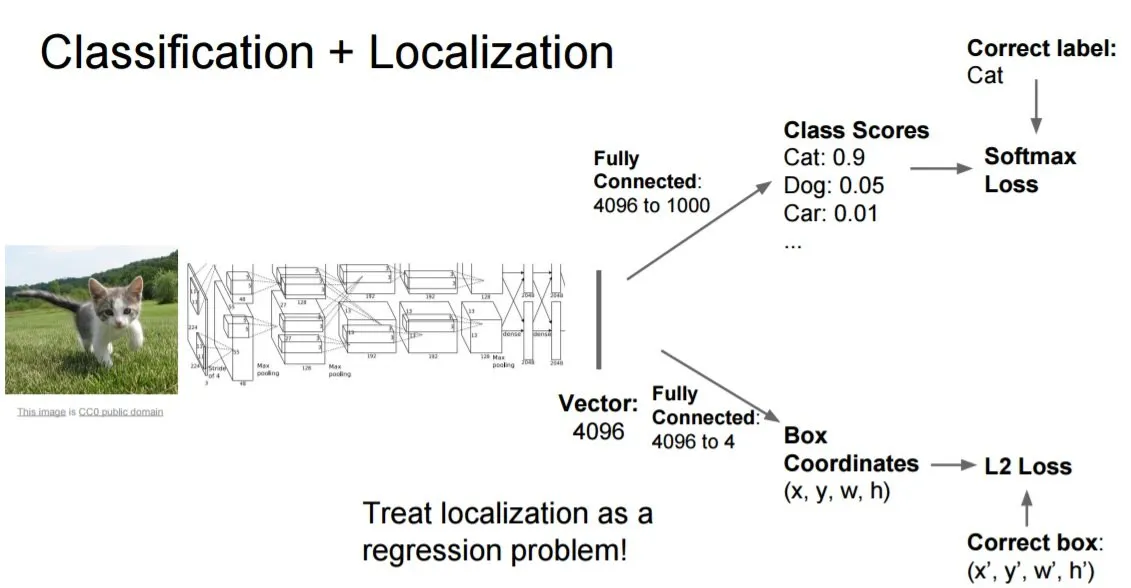
视频的基本形式只是一连串的图片。对于视频中的每个图像(我们称之为帧,如60 帧就等于每秒60张图像)。我们会人手划出图片中的猫的坐标,因此在这个2D图片上将有4个数字,以便在对象(猫)周围形成一个矩形。 所以最后,我们的数据可以描述为很多对的图片和该图片中的4个坐标数。
猫和箭头之间的盒子是什么?
他们一般会包括Convolution和Maxpool,这里是一个例子。
Convolution和Maxpool:用于图像处理(包括Alpha Go的应用)中的技术,将图像缩细为较小的帧。这使得模型能够考虑更少的像素用于决策,同时保持良好的效果(在大多数情况下甚至更好)。
想了解更多有关图像处理的信息?查看我关于自驾AI的博客: https://steemit.com/gaming/@jimsparkle/using-ai-to-self-piloting-x-wing-in-star-wars-battlefront-with-howto-and-code
训练
所以机器一开始会为图片随机生成4个数字,并将其与真实坐标进行比较,然后调整模型以产生下一组更好的4个数字。 如果机器自己训练数日,就能得到相当满意的效果。这总结了Facebook如何检测我们的脸,特斯拉检测到交通灯,并且FBI如何检测到您!