🌐 GitHub - openhive-network/haf: Hive Application Framework for building robust and scalable Hive APIs and apps. HAF servers collect blockchain data from a hived node, providing a standardized SQL database for defining general-purpose and app-specific APIs for Hive.
Overview of the Hive Application Framework (HAF) The Hive Application Framework
was developed to simplify the creation of highly scalable, blockchain-based
applications.
HAF-based apps are naturally resilient against blockchain forks because HAF
contains a mechanism for automatically undoing data generated by forked out
blocks.
HAF servers act as an intermediary between the Hive network and Hive
applications.
HAF-based applications do not normally read data directly from Hive nodes (aka
hived process) via a pull model.
Instead, HAF applications receive blockchain data via a push model: a hived node
is configured with a sql_serializer plugin that processes each new block as it
arrives at the hived node and writes the associated blockchain data
(transactions, operations, virtual operations, etc) to a Postgres database.
The server where this Postgres database is running is referred to as a HAF
server.
Multiple HAF-based apps can run on a single HAF server, sharing the same HAF
database, with each HAF app creating a separate schema where it stores
app-specific data.
Since HAF servers receive their data via a push model, they impose a fixed
amount of load on the hived node that supplies blockchain data, regardless of
the number of HAF apps running on the server.
In other words, while too many apps may load down the postgres database and
affect the performance of other apps, the hived node supplying the data should
continue to function without any problems.
HAF-app users publish transactions on the Hive network when they want to send
data to a HAF-based app.
Typically these transactions contain custom_json operations that contain
information specifically customized for one or more HAF apps.
These operations then get included into the blockchain and thereafter inserted
into the HAF database for further processing by any HAF application that is
watching for those particular operations.
In other words, user actions aren't directly sent to app servers.
Instead, they are published to the hived peer-to-peer network, included into the
decentralized storage of the Hive blockchain, and then indirectly processed by
HAF servers reading data from the blockchain.
An understanding of Hive's custom_json operations is critical to developing an
interactive Hive app.
A custom_json operation allows a user to embed one or more pieces of arbitrary
json data into a Hive transaction.
Interactive hive apps can utilize this feature to create a set of "commands"
that their app recognizes and will process when a user publishes a transaction
containing those commands.
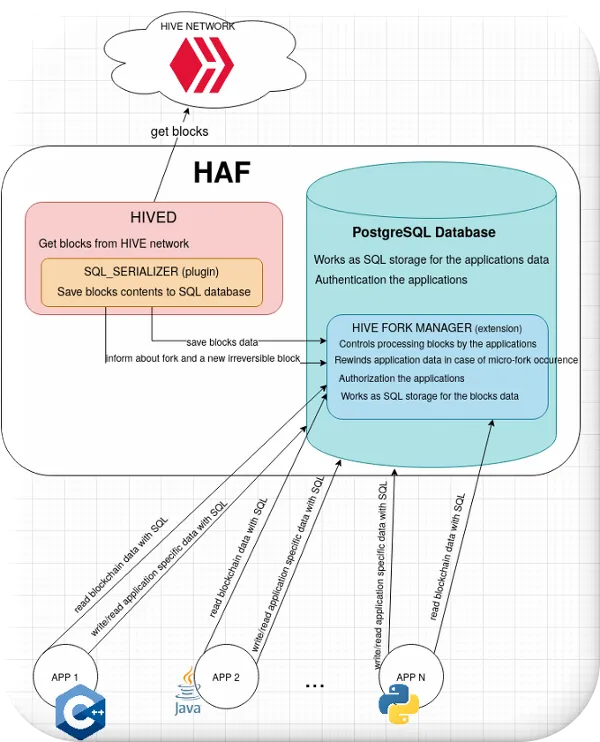
The image above shows the main components of a HAF installation: HIVED HAF
requires a hived node which syncs blocks with other hived nodes in the Hive
peer-to-peer network and pushes this data into the HAF database.
This hived node doesn't need to be located on the HAF server itself, although in
some cases this may allow for faster filling of a HAF database that needs to be
massively synced (i.e.
when you need to fill a database with a lot of already-produced blockchain
blocks).
SQL_SERIALIZER sql_serializer is the hived plugin which is responsible for
pushing the data from blockchain blocks into the HAF database.
The plugin also informs the database about the occurrence of microforks (in
which case HAF has to revert database changes that resulted from the forked out
blocks).
It also signals the database when a block has become irreversible (no longer
revertable via a fork), so that the info from that block can be moved from the
"reversible" tables inside the database to the "irreversible" tables.
Detailed documentation for the sql_serializer is here:
src/sql_serializer/README.md PostgreSQL database A HAF database contains data
from blockchain blocks in the form of SQL tables (these tables are stored in the
"hafd" schema inside the database), and it also contains tables for the data
generated by HAF apps running on the HAF server (each app has its own separate
schema to encapsulate its data).
The system utilizes Postgres authentication and authorization mechanisms to
protect HAF-based apps from interfering with each other.
HIVE FORK MANAGER is a PostgreSQL extension that implements HAF's API inside the
"hive" schema.
This extension must be included when creating a new HAF database.
This extension defines the format of block data saved in the database.
It also defines a set of SQL stored procedures that are used by HAF apps to get
data about the blocks.
The SQL_SERIALIZER dumps blocks to the tables defined by the hive_fork_manager
in 'hafd' schema.
This extension defines the process by which HAF apps consume blocks, and ensures
that apps cannot corrupt each other's data.
The hive_fork_manager is also responsible for rewinding the state of the tables
of all the HAF apps running on the server in the case of a micro-fork
occurrence.
Detailed documentation for hive_fork_manager is here:
src/hive_fork_manager/Readme.md HAF server quickstart NOTE: The fastest and
easiest way to install and maintain a HAF server is to use the docker compose
scripts in this repo: https://gitlab.syncad.com/hive/haf_api_node But if you
prefer to build your own HAF docker image, you can follow the steps below: git
clone --recurse --branch develop https://gitlab.syncad.com/hive/haf.git mkdir -p
workdir/haf-datadir/blockchain cd workdir
../haf/scripts/ci-helpers/build_instance.sh local-develop ../haf/
registry.gitlab.syncad.com/hive/haf Now you can either sync your hived node from
scratch via the Hive P2P network, or you can download a copy of the blockchain's
block_log file from a location you trust (e.g.
https://gtg.openhive.network/get/blockchain/compressed/block_log) and replay the
block_log.
The latter method is typically faster, because a replay doesn't re-validate the
blocks, but the first method (syncing from scratch) requires the least trust.
To start your HAF server, type: ../haf/scripts/run_hived_img.sh
registry.gitlab.syncad.com/hive/haf:local-develop --name=haf-instance
--webserver-http-endpoint=8091 --webserver-ws-endpoint=8090
--data-dir=$(pwd)/haf-datadir --replay If you don't have a local block_log file,
just remove the --replay option from the command line above to get the
blockchain blocks using the P2P network via the normal sync procedure.
It is advisable to have your own custom PostgreSQL config file in order to have
PostgreSQL logs available locally and specify custom database access
permissions.
To do that, before starting your HAF server, just copy doc/haf_postgresql_conf.d
containing configuration files where you can override any PostgreSQL setting.
The steps above should create a haf-datadir/haf_db_store subdirectory containig
a PostgreSQL database holding HAF data and haf-datadir/hived.log containing the
output of the underlying hived process.
Use docker container stop haf-instance to safely stop the service.
See dockerized deployment details for further details.
HAF manual build and deloyment steps are described here:
doc/HAF_Detailed_Deployment.md
🔒 ARCHIVE VERIFICATION CERTIFICATE
Cryptographic authenticity and integrity verificationSource:
View Article| Method: enhanced_sessionStatus: ✅ Complete | Words: 📊 1042
Content Hash:
2f7f38e5d8cc418eb70ffd09377abb166ef50d363929b890908dc4544c8cdc78
HTML Hash:2f7f38e5d8cc418eb70ffd09377abb166ef50d363929b890908dc4544c8cdc78
Blockchain Hash:957ece1d7da287628d86962d1f6192abb89bc4e240760649fcc31062b1d66e7d
Server: github.com | Type: unknown
SSL Cert: 🔒 TLSv1.3 | Certificate Authority |certificate
Blockchain Proof:957ece1d7da287628d86962d1f6192abb89bc4e240760649fcc31062b1d66e7d
Blockchain: ✅ Yes | Verified: 2025-06-13T14:54:53.415370
Status: ✅ Cryptographically VerifiedArchived for historical preservation ⚖️
ArcHive Professional