Momentan schau ich grad so ein Projektvideo von Udemy an, wo es um Webcrawler geht. Da bin ich zwar erst ziemlich am Anfang, aber das Interesse hat mich ziemlich gepackt, denn so etwas wollte ich schon häufiger verwenden. Wie oft habe ich nach Artikeln gesucht, die dann nur mehr zu finden waren, weil ich zufällig noch einen Link irgendwo hatte. Suchmaschine? Häufig Fehlanzeige. Manchmal mit hirnrissig, verzweifelten Suchmethoden.
Dann gibt es Programme, die können (soweit, die Seiten keine Sperren haben), die ganze Homepage kopieren; allerdings auf Dauer eine Katastrophe für den Speicherplatz.
Die jetzige Lösung gewinnt bestimmt keinen Schönheitswettbewerb, sie macht aber das was sie tun soll. In diesem Fall habe ich Python mit Linux-Shellscripting gemischt, um an das gewünschte Ergebnis zu kommen. Bestimmt wäre es mit Python alleine auch gegangen.
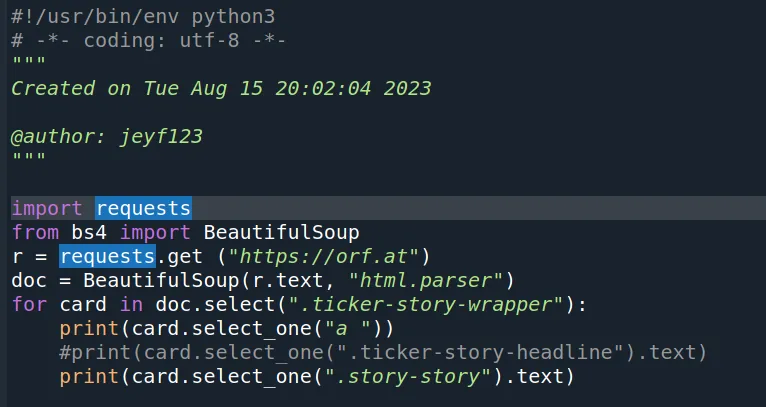
Von orf.at werden 2 Elemente gesucht, der Nachrichtenlink (den gibts inkl. Headline, aber leider konnte ich noch nicht den anderen html-Unsinn rausfiltern) und die Nachricht dazu selbst. (Es gäbe auch einen css.Selektor für Headlines alleine, das ist aber sinnlos in diesem Fall). Diese werden dann vom Shellscript(bin froh, dass dieser Übergang so harmlos funktioniert hat) in eine Textdatei umgewandelt. Der Vorgang wird automatisch durch sleep alle 6h wiederholt. Neue Downloads werden mit einer Uhrzeit versehen, und dann hintan an den vorhandenen Text eingefügt. Fairerweise muss ich sagen, dass es mit cron vermutlich etwas eleganter gewesen wäre. Vielleicht baue ich das noch ein.
In Summe hab ich mir ausgerechnet, dass die Methode in etwa 20MB pro Jahr brauchen wird. Vielleicht, dass ich für Lesbarkeitszwecke noch ein paar Routinen einbaue.
PS.: Das wollte ich eigentlich noch sagen; innerhalb von 6h können natürlich auch noch alte Artikel stehen, die sich im Text wiederholen. Das ist etwas ifeffizient, aber ich hab mich noch nicht mit if irgendwas in irgendwas_anderes.. beschäftigt, beim Webcrawler

#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 15 20:02:04 2023
@author: jeyf123
"""
import requests
from bs4 import BeautifulSoup
r = requests.get ("https://orf.at")
doc = BeautifulSoup(r.text, "html.parser")
for card in doc.select(".ticker-story-wrapper"):
print(card.select_one("a "))
#print(card.select_one(".ticker-story-headline").text)
print(card.select_one(".story-story").text)