
➡Link to the article in English ⬅
SteemSQL est la base de données qui regroupe toutes les informations en rapport avec Steemit : Les caractéristiques des comptes, le contenu des articles postés, les différentes informations liées au fonctionnement de Steemit (upvote, reblog,..) etc…
Une base de données est un outil informatique qui permet de stocker et d’organiser des données de façon structurée. Au même titre qu’un fichier excel, différentes tables sont créées et mise en relation à l’aide d’identifiants uniques, ce qui permet d’obtenir des données variées en rapport avec un élément en particulier.
Un grand nombre d’outils développés pour la plateforme Steemit se reposent sur la base de données SteemSQL.
Quelques exemples d’outils indispensables pour bien comprendre l’écosystème de Steemit :
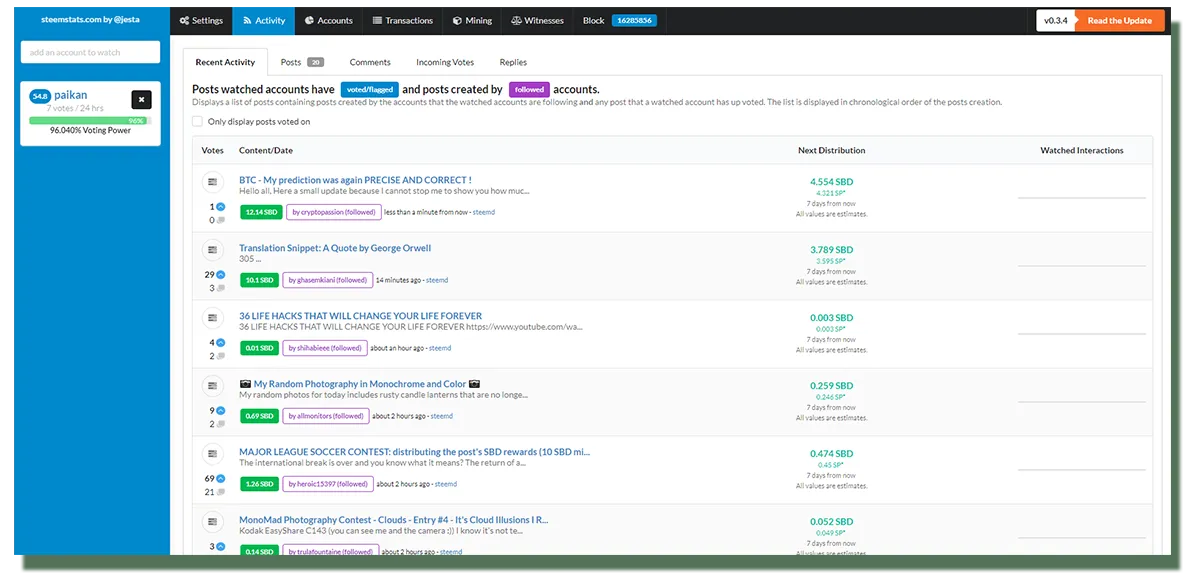
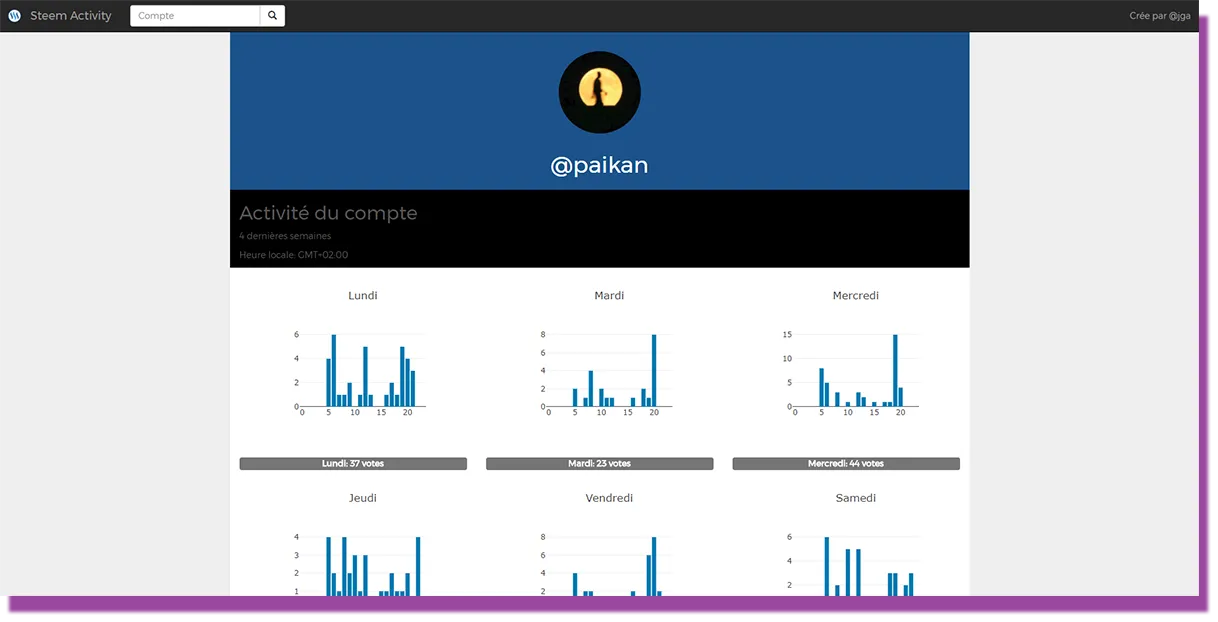
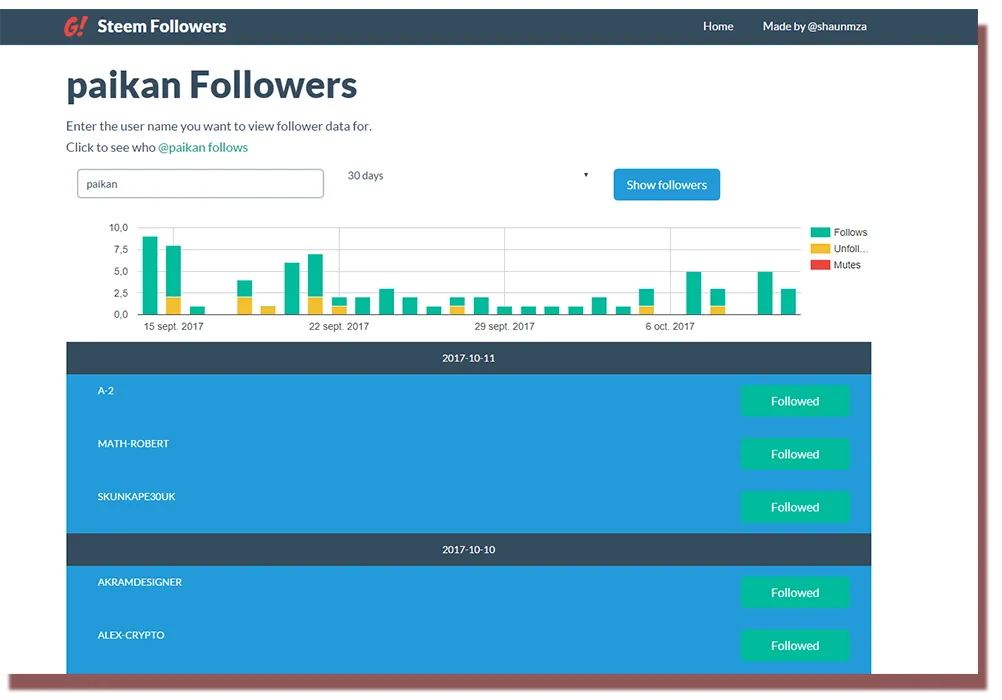
Comment utiliser SteemSQL
Afin d’accéder à la base de données, nous avons besoin d’un logiciel appelé (Système de Gestion de Base de Données - SGBD). Il existe beaucoup de SGBD qui offre la possibilité de se connecter à une base de données, je vous propose SQL Server Management Studio (SSMS), édité par Microsoft, il est gratuit est relativement simple à utiliser.
Une fois le SGBD lancé, nous allons créer une nouvelle connexion vers la base de données SteemSQL.
Cliquer sur l’onglet « Nouvelle connexion » et rentrer les informations suivantes :
- Nom du serveur : sql.steemsql.com
- Connexion : steemit
- Mot de passe : steemit
Puis se connecter.
Astuce ! Si vous ne voyez pas la base SteemSQL apparaitre, ouvrez une nouvelle requête et tapez « USE DBSteem » puis ‘F5’ ou ‘Executer’
Nous voilà maintenant connecté à la base de données.
Comment récupérer les informations de SteemSQL
Maintenant nous allons lancer des requêtes sur le serveur pour récupérer différentes information, le langage utilisé est le Transact SQL, langage développé par la société Sybase, il est devenu avec le temps le principale langage de programmation pour les outils Microsoft.
IMPORTANT : Si vous souhaitez faire vos tests, n’oubliez jamais de mentionner (NOLOCK) après le nom des tables, c’est une question de performance, il est inutile de bloquer les transactions pour effectuer de simples tests.
Requête : Donne-moi les informations en rapport avec un utilisateur

Requête : Donne-moi les caractéristiques des 20 comptes qui ont le plus de réputation
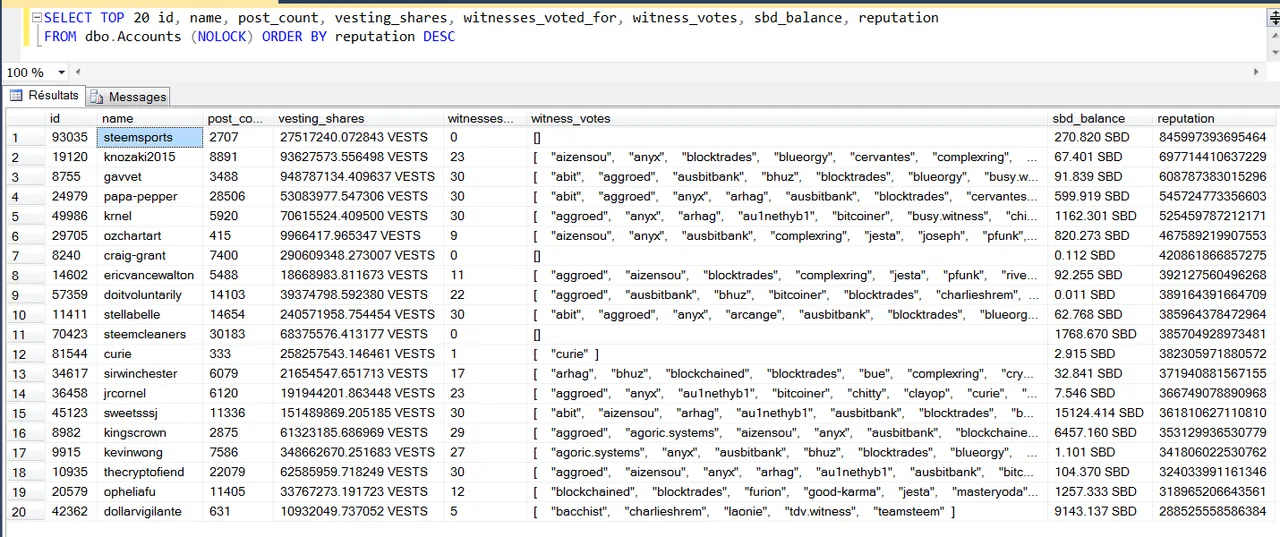
Analyse : Je n’ai pas encore suffisamment de recule pour analyser finement les résultats. Mais je constate que @curie et @ozchartart se retrouve dans le top 20 des réputations avec très peu d’articles, surement une question de qualité. Je remarque aussi que @abit, @aggroed et @anyx sont des witness très populaires, la raison doit être justifiée.
Dans le cas où vous souhaitez participer à un contest, il peut être intéressant de chercher les contest qui ont le plus de visibilité.
Requête : Affiche moi les 20 articles qui contiennent le mot « contest » dans leurs titres, qui ont été publiés il y a moins de 4 jours et classe les résultats par nombre de vote.
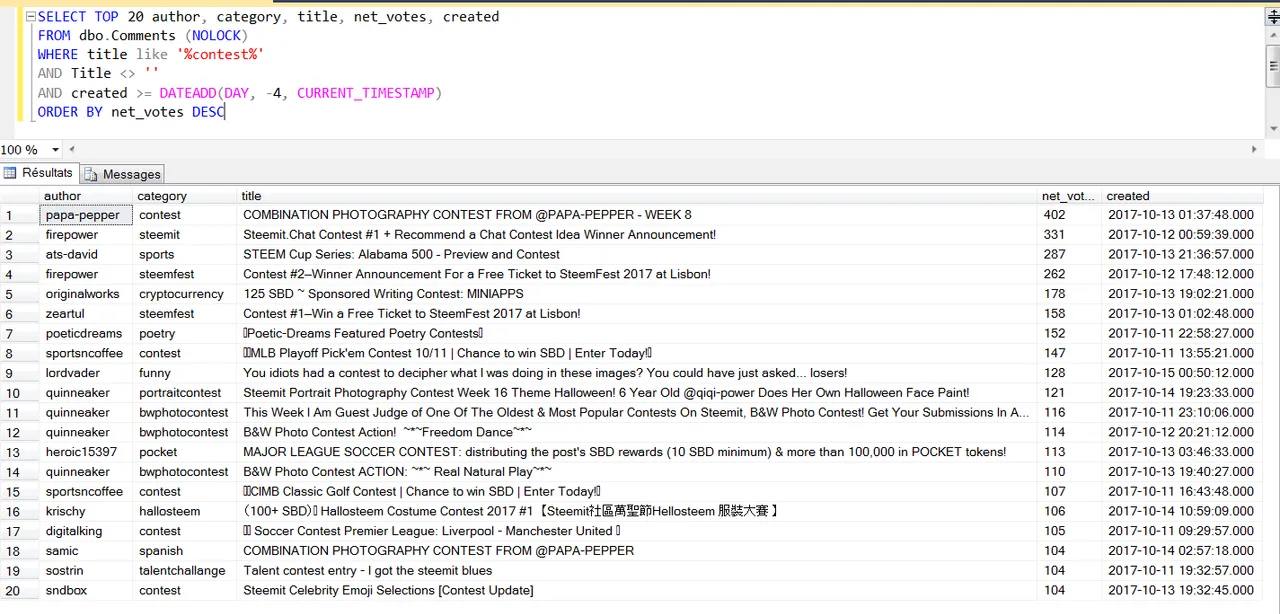
Analyse : Le résultat est intéressant, @originalworks organise un concours à 125 SBD, @quinneaker et @papa-pepper sont des habitués des concours photo :)
Ces premiers exemples sont des requêtes simples, toute la puissance des bases de données relationnelles se trouve dans la possibilité de faire des jointures entre plusieurs tables. Liées par des identifiants uniques, il est possible de récupérer un grand nombre d’informations en utilisant ces liaisons.
Pour parler d’un sujet qui nous passionne, rien de mieux que de se tourner vers des auteurs de qualité qui abordent régulièrement le sujet.
Requête : Affiche-moi le nom de l’auteur, sa réputation, le titre de son article et l’url des articles dont le titre contient le mot ‘cryptomonnaie’, qui ont été publiés il y a moins de 45 jours et classe les résultats par réputation.
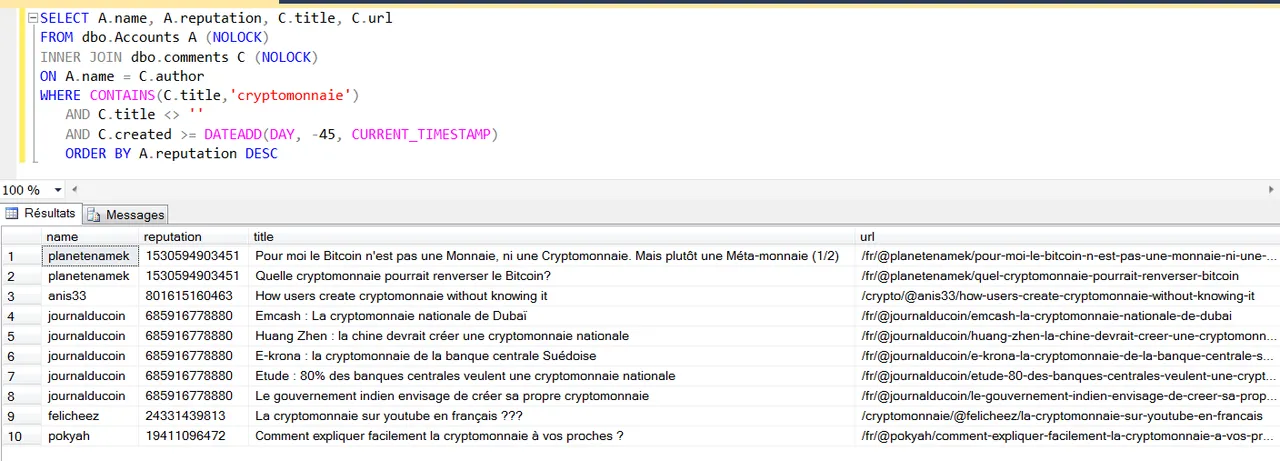
Analyse : Je dois avouer que je ne suis pas très fort en crypto monnaie, au vue des résultats, je me dis que si je souhaite échanger sur le sujet autant me tourner vers @planetenamek ou @journalducoin, ils sont surement au courant des dernières nouveautés.
Comme je vous l’ai dit, tout est stocké dans la base, non seulement les articles et les utilisateurs mais les commentaires également. Si votre souhait est de garder une visibilité sur votre présence, vous pouvez demander à la base de vous afficher tous les commentaires ou votre pseudo apparaît.
Requête : Affiche moi, l’auteur du commentaire, le titre de l’article parent et le corps du message de tous les commentaires qui contiennent mon pseudo.
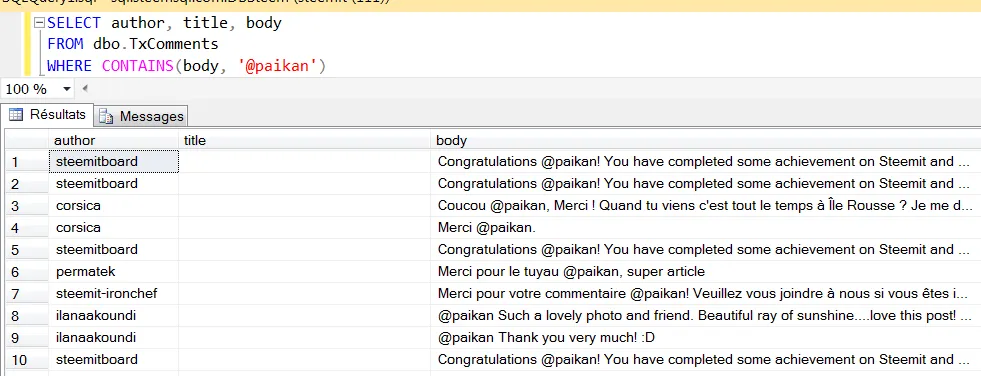
Les tables de la base de données
Je n’ai pas pris le temps de chercher et de parcourir toutes les tables. Pour réaliser cet article je me suis reposé sur un schéma existant, réalisé par @arcange et présent dans son article :
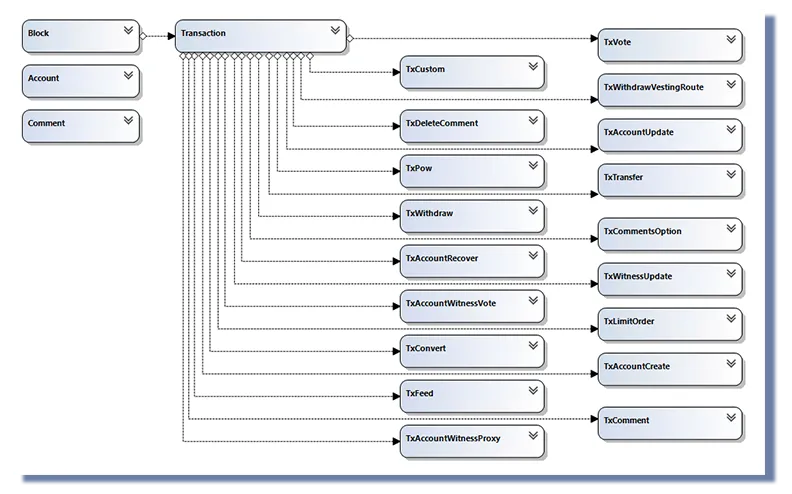
Cet article a pour but de présenter les principes de l’accès en base de données. Mes requêtes sont extrêmement simples mais il est possible de réaliser des requêtes et des procédures extrêmement puissantes. N’oubliez surtout pas qu’une très grande partie du fonctionnement de Steemit repose sur la base de données qui stock les données.
J’en profite également pour remercier @arcange pour le travail qu’il réalise sur la base SteemSQL, pour ses optimisations ou ses développement qui nous permettent à tous d’accéder à Steemit avec des temps de réponse très acceptables :)
Je vous rappelle que vous pouvez voter pour lui en tant que Witness et n’hésitez pas à rejoindre le chat steemsql pour toutes questions techniques.