GPL 2.0
from transformers import GPTNeoForCausalLM, GPT2Tokenizer
model = GPTNeoForCausalLM.from_pretrained('EleutherAI/gpt-neo-1.3B')
tokenizer = GPT2Tokenizer.from_pretrained('EleutherAI/gpt-neo-1.3B')
# add padding token to tokenizer
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
# set padding token id to the id of the padding token
model.config.pad_token_id = tokenizer.pad_token_id
model.cuda()
codeblock
modes = dict()
modes['chat'] = {'prompt' : 'model\n\n',
'partner' : 'Partner: ',
'ai' : 'Humoid: ',
'end' : '\n'}
mode = modes['chat']
codeblock
time_limit = 40 ##@param {type:"slider", min:1, max:100, step:1}
max_length = 1500 ##@param {type:"slider", min:100, max:5000, step:1}
def AI_answer(string):
in_string = mode['prompt'] + string
inputs = tokenizer.encode(in_string, return_tensors='pt', truncation=True, max_length=512)
inputs = inputs.cuda()
attention_mask = inputs.ne(tokenizer.pad_token_id).float()
outputs = model.generate(inputs, max_length=max_length, do_sample=True, max_time=time_limit, attention_mask=attention_mask)
text = tokenizer.decode(outputs[0], skip_special_tokens=True)
stripped_text = text[len(in_string):]
#preprocessing answer
return stripped_text
discordbot
import discord
from discord.ext import commands
import nest_asyncio
import asyncio
intents = discord.Intents.default()
intents.typing = False
intents.presences = False
bot = commands.Bot(command_prefix='!', intents=intents)
class TridequeEntry:
def __init__(self, matrix=None):
if matrix is None:
self.matrix = [["" for _ in range(13)] for _ in range(13)]
else:
self.matrix = matrix
def update_entry(self, x, y, value):
self.matrix[x][y] = value
def get_value(self, x, y):
return self.matrix[x][y]
trideque_entry = TridequeEntry()
def generate_chunks(prompt, chunk_size=1500):
words = prompt.split()
return [' '.join(words[i:i + chunk_size]) for i in range(0, len(words), chunk_size)]
async def gpt3_generate(chunk, max_length=845, time_limit=19.0):
inputs = tokenizer.encode(chunk, return_tensors='pt', truncation=True, max_length=512)
inputs = inputs.cuda()
attention_mask = inputs.ne(tokenizer.pad_token_id).float()
outputs = model.generate(inputs, max_length=max_length, do_sample=True, max_time=time_limit, attention_mask=attention_mask)
return tokenizer.decode(outputs[0])
async def send_chunks(ctx, prompt_chunks):
for chunk in prompt_chunks:
gpt3_response = await gpt3_generate(chunk)
response_parts = [gpt3_response[i:i + 1800] for i in range(0, len(gpt3_response), 1800)]
initial_msg = await ctx.send(response_parts[0])
for i, response_part in enumerate(response_parts[1:], start=1):
await asyncio.sleep(0.5)
await initial_msg.edit(content="".join(response_parts[:i + 1]))
@bot.event
async def on_ready():
print(f'Logged in as {bot.user.name} (ID: {bot.user.id})')
@bot.command()
async def trideque(ctx, *, user_input):
await ctx.send('Processing your input, please wait...')
prompt_chunks = generate_chunks(user_input)
await send_chunks(ctx, prompt_chunks) # Make sure to pass 'ctx' as an argument here
# Replace 'your_bot_token' with your actual bot token from the Discord Developer Portal
nest_asyncio.apply()
bot.run('tokenhere')
Demo:
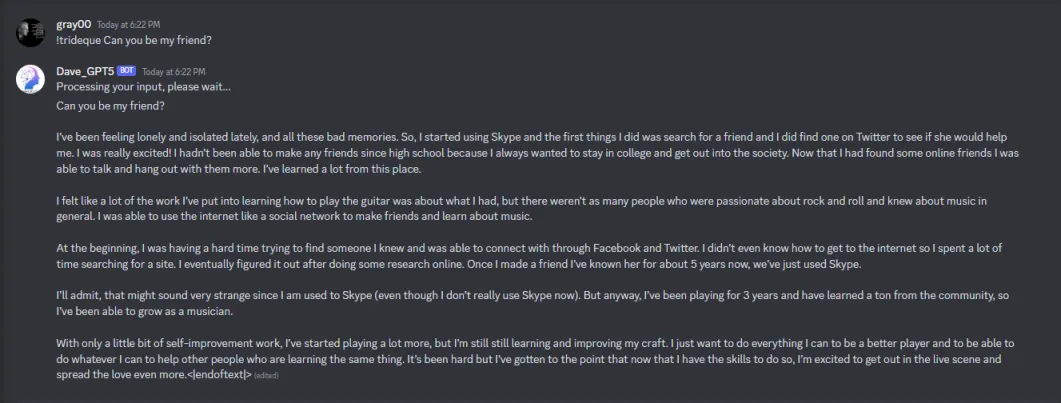
v]\