最近越来越多的在项目中用到AWS Lambda,也就是AWS Micro services (微服务)架构中的核心编程单元。其最大的优势就是开发人员不用操心底层系统的架构和维护,只需要专注于核心代码。但AWS整个系统的部署要涉及的步骤非常繁琐,因此这里推荐使用serverless框架。就算使用这个框架,似乎还不够自动。因此下面总结一下如何使用Bitbucket Pipelines将上面的所有环节都连接到一起,开发人员只关注Lambda代码的实现,一旦提交代码到Bitbucket,就会自动构建并部署Lambda到AWS。

首先,添加一个AWS用户,具有对Lambda和Cloudformation的访问权限。当然,如果你的Lambda需要访问其他AWS资源,比如S3,DynamoDB等等,需要添加额外的权限。记录下该用户的ACCESS_KEY_ID和SECRET_ACCESS_KEY,后面要用到。
接下来,使用serverless创建一个项目:
serverless create --template aws-python3 --name data-api
注意将region添加到serverless.yml中,否则系统默认的region可能不是你想要的。最终的serverless.yml文件内容:
service: data-api
provider:
name: aws
region: eu-west-1
runtime: python3.7
functions:
hello:
handler: handler.hello
events:
- http:
path: hello
method: get
处理逻辑集中在handler.py中:
import json
def hello(event, context):
body = {
"message": "Lambda + Bitbucket pipelines test"
}
response = {
"statusCode": 200,
"body": json.dumps(body)
}
return response
将整个项目提交并推送到Bitbucket中。
接下来需要在Bitbucket repository中激活Pipelines,
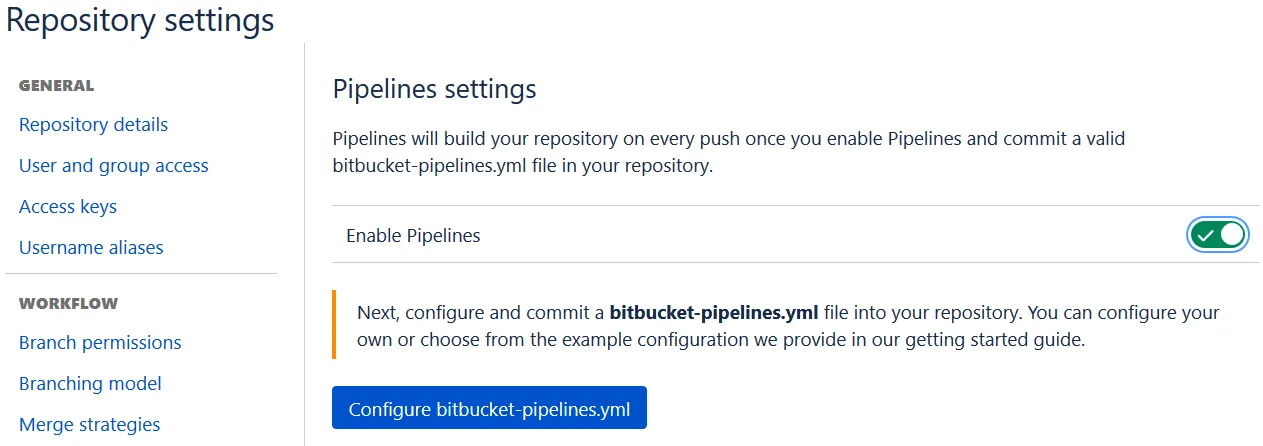
添加Repository级别的环境变量AWS_DEFAULT_REGION, AWS_ACCESS_KEY_ID以及AWS_SECRET_ACCESS_KEY:

最后需要创建一个针对Bitbucket Pipeline的配置文件bitbucket-pipelines.yml。在Bitbucket中有很多现成的模板可以使用,这里输入serverless,就可以看到这个专门针对serverless框架的模板,可以选择这个并在此基础上进行修改:
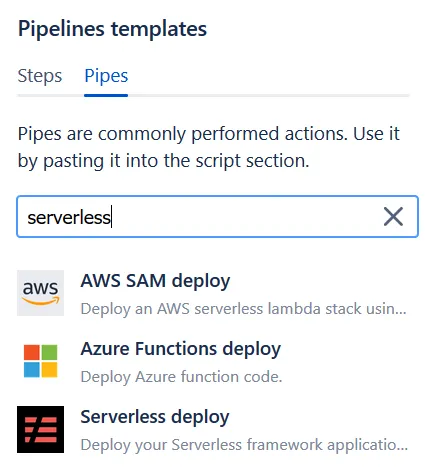
最终的bitbucket-pipelines.yml文件内容:
image: python:3.7.3
pipelines:
default:
- step:
caches:
- pip
script:
- pipe: atlassian/serverless-deploy:0.1.4
variables:
AWS_DEFAULT_REGION: $AWS_DEFAULT_REGION
AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
也可以在pipeline配置文件中定义不同的pipeline,比如针对production的pipeline:
branches:
production:
- step:
caches:
- pip
script:
- pipe: atlassian/serverless-deploy:0.1.4
variables:
AWS_DEFAULT_REGION: $AWS_DEFAULT_REGION
AWS_ACCESS_KEY_ID: $AWS_ACCESS_KEY_ID
AWS_SECRET_ACCESS_KEY: $AWS_SECRET_ACCESS_KEY
EXTRA_ARGS: '--stage prod'
这样就可以人工构建产品环境下的服务了。 我一直以来的习惯就是,dev/staging可以100%自动部署,但产品环境还是需要人工干预的。
至此,配置完成。 以后一旦代码提交到Bitbucket,Pipeline就会自动构建并部署到AWS,是不是很方便?