参考:
youtube-gpt |
Chatbot
我们都知道现阶段ChatGPT的数据是只到2021年,之后的事情它就不知道了。那么,怎么解决这个问题呢?同样,在特别专门的领域,如何使ChatGPT更专业呢?这时,嵌入(Embeddings)就要出场了。
嵌入(Embeddings)是一个浮点数字的向量(列表)。两个向量之间的距离衡量它们的关联性。它可以用于事先对模型的数据准备,也就是更新模型的新数据。例如chatgpt的数据只到2021年,没有后面的数据,或是专门类的数据不够,它就不会得到正确答案。这时,可以先准备新数据的嵌入向量,查询时先通过向量查询出新数据,把新数据一起传入chatgpt以得到正解。所以,嵌入(Embeddings)是给chatgpt投喂新数据。
简单讲,嵌入(Embeddings)就是提前给ChatGPT准备关联度很高的数据以解决其特定方面的缺乏。按此思路,我们可以把ChatGPT定制成专门用途或是专门领域的AI助手,比例法律小顾问,俄乌"砖家"......
下面是俄乌"砖家"的诞生过程:
const { Configuration, OpenAIApi } = require("openai");
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
const response = await openai.createEmbedding({
model: "text-embedding-ada-002",
input: "The food was delicious and the waiter...",
});
//response response.data.data[0].embedding
eg:
let jsonData = [
{
"text": "2022年1月10号到13号,俄罗斯分别与美国和北约开展对话.......",
"embedding": [
-0.012431818,
-0.021277534, ......
]
},
{
"text": "美国国防部宣布:将向欧洲增派部队,应对俄乌边境地区的紧张局势.....",
"embedding": [
-0.012431818,
-0.021277534, ......
]
}
]
//查找两段文本的相似度
function cosineSimilarity(vecA, vecB) {
let dotProduct = 0
let normA = 0
let normB = 0
for (let i = 0; i < vecA.length; i++) {
dotProduct += vecA[i] * vecB[i]
normA += Math.pow(vecA[i], 2)
normB += Math.pow(vecB[i], 2)
}
return dotProduct / (Math.sqrt(normA) * Math.sqrt(normB))
}
//从数据集中查找拟合度最高的两段文本
function getSimilarTextFromDb(inputEmbedding, jsonData) {
let result = []
jsonData.forEach(embedding => {
let similarity = cosineSimilarity(inputEmbedding, embedding.embedding)
// console.log("similarity", similarity)
if (similarity > 0.8) {
result.push({
text: `${embedding.text}`,
similarity: similarity
})
}
})
result.sort((a, b) => b.similarity - a.similarity)
let topTwo = result.slice(0, 2)
return topTwo.map(r => r.text).join("")
}
//1. 先是查找文本的向量值
//2. 再和预先准备的数据集比对,选出拟合度最高的文本
//3. 选出的文本和用户的关键词拼接,再查询
const prompt = req.body.prompt
const inputEmbeddingResponse = await openai.createEmbedding({
model: "text-embedding-ada-002",
input: prompt
})
const inputEmbedding = inputEmbeddingResponse.data.data[0].embedding
const context = getSimilarTextFromDb(inputEmbedding, jsonData)
// console.log(289,"getSimilarTextFromDb", context)
let promptX = `我希望你充当俄罗斯和乌克兰的问题专家。我会向您提供有关俄罗斯和乌克兰问题所需的所有信息,而您的职责是用简易和严谨的语言解答我的问题。\n${context}\n${prompt}`
const response = await openai.createCompletion({
model: "text-davinci-003",
prompt: promptX,
temperature: 0.2,
max_tokens: 3000,
top_p: 1,
frequency_penalty: 0,
presence_penalty: 0,
})
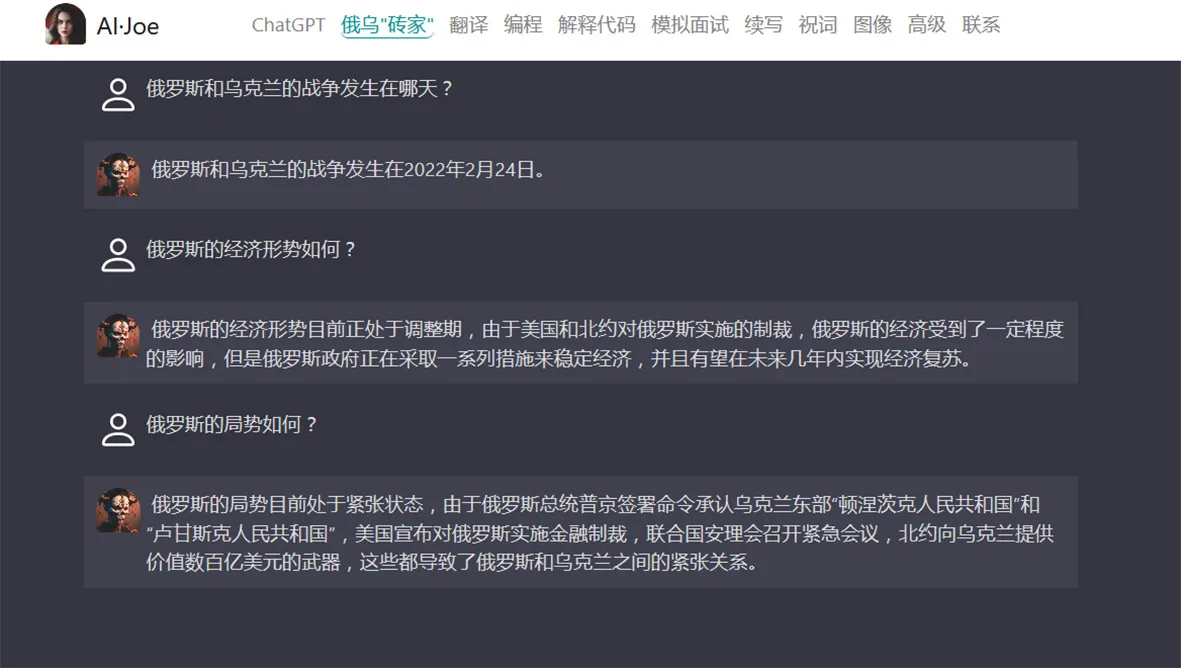
俄乌"砖家"跑起来之后,投喂了些最新的数据和进展。再去查它时,表现就截然不同啰!比如“俄罗斯和乌克兰的战争发生在哪天?”这个问题,原ChatGPT都是回答不知道的,比如这样的答案“俄罗斯和乌克兰的战争并没有具体的发生日期,它是一场持续多年的冲突。最初的冲突可以追溯到2014年克里米亚危机,随后在乌克兰东部地区爆发了武装冲突。截至2021年,冲突仍在持续。”。现在的俄乌"砖家"经过投喂,就可以给出正确的答案了!
以此类推,还有很多可以展开的应用场景......