前天折腾了一整天图片转表格并以失败告终,还被媳妇一通嘲笑,哎,郁闷呀。为了不被她看扁,我决定一定要把期中考试的成绩表弄出来。

(图源 :pixabay)
话说,PadlleOCR没安装明白(安装成功之后不好用),EasyOCR安装倒是出奇地顺利,但是对付简单的英文表格尚可,期中成绩表识别得一塌糊涂。
那么是否还有其它可用的OCR方案呢?看了一下img2table支持的OCR服务还真不少:

咦,AWS竟然也有OCR服务:Textract,不过简单研究了一下,这个Textrac和上边我提到的两种OCR方案是有所区别的,之前的两种都是把OCR工具以及识别模型部署到本地,而Textract本质上把数据上传到AWS,然后再返回识别的内容。
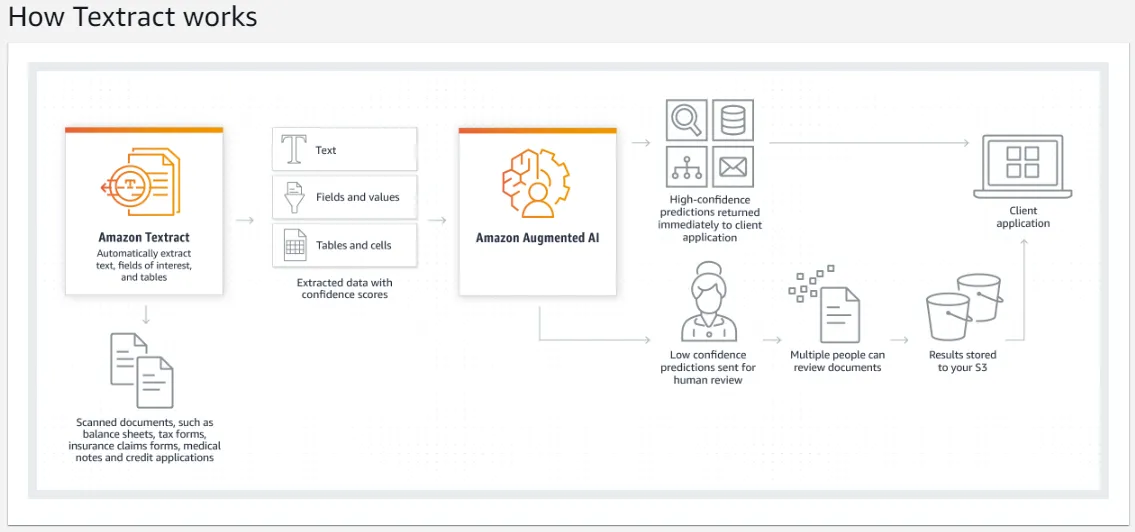
并且和上述两个OCR方案是免费提供的不同,Textract是要花费Money的:
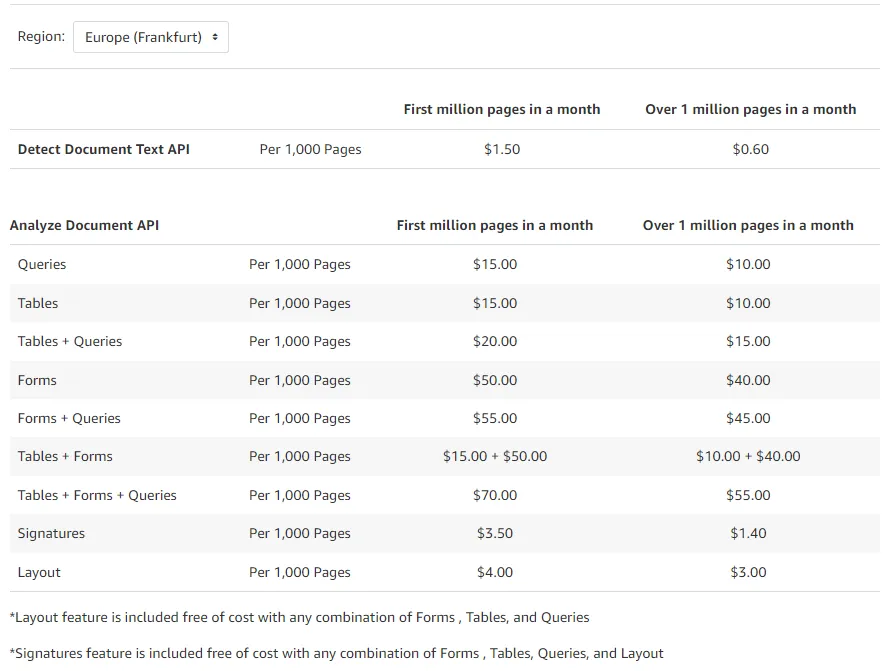
这个价格咋说呢?如果我每月就识别几张表格,那么还要花费$15的费用,简直是亏大了。如果有pay as you go,计费方案,折合算下来每页倒是很便宜,可惜没找到这样的计费方式。
总之,对我这种每月识别不了几张表格的人,费尽周折弄一些API接入,再每月被扣费$15,用Textract太不合算啦。
然而,当我即将果断放弃时,我注意到页面上这样一组字样:

这是什么意思?是我可以免费试用Textract工具嘛?不用和API打交道?这倒是极有吸引力呀?点开看看
首先映入眼帘的是一个文档识别的示例,从示例上可见是相当之强大:
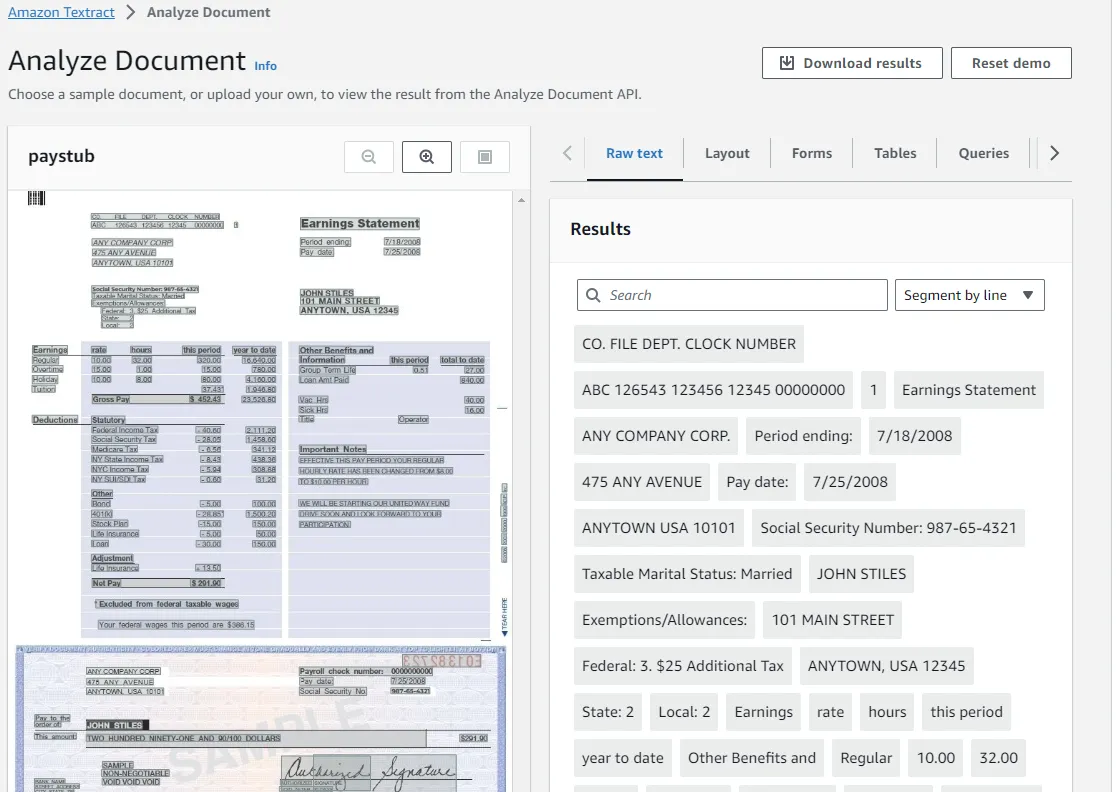
在其下方,可以选择示例文档,也可以自己穿文档,那当然是自己上传了,哈哈哈
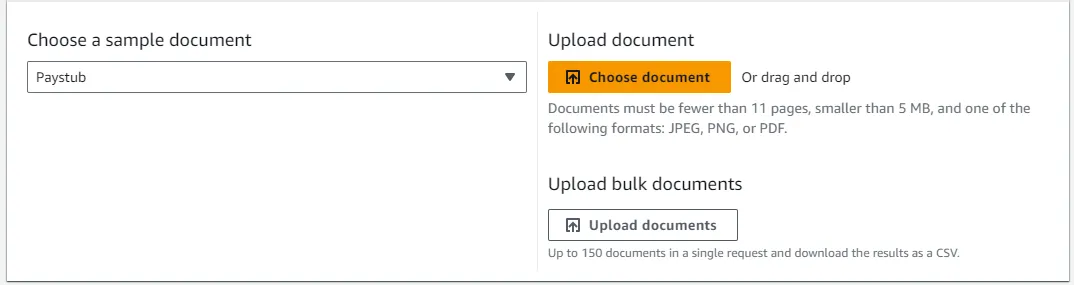
我们选择从本地上传:
上传文档中:
上传成功:

在这里选择如何处理文档,我选择的表格:
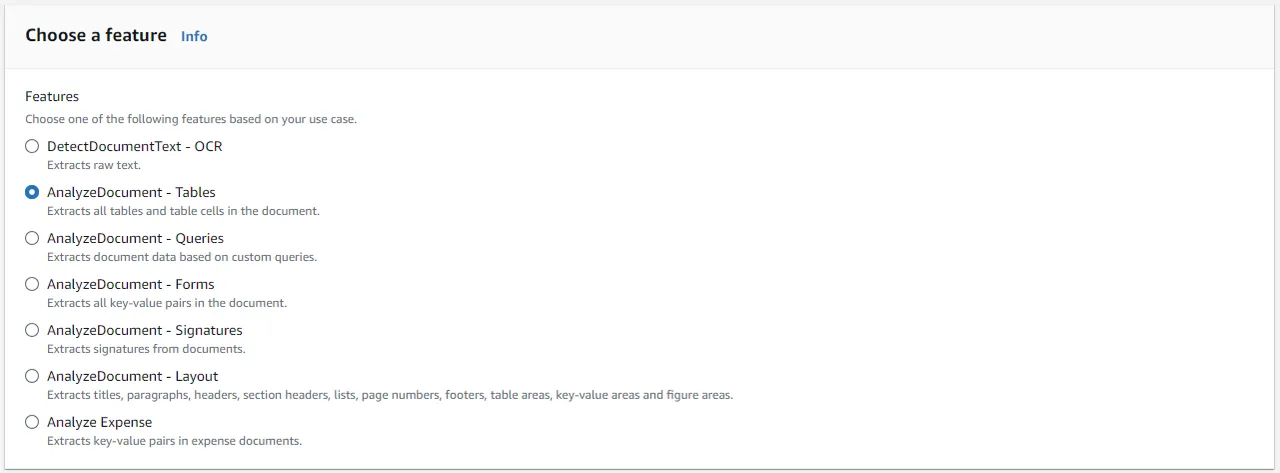
处理中

处理完成

选中后,下载按钮(Download result)变为可用,我们就可用将其下载到本地啦。
下载完成并解压后,发现文件夹中包含两个文件:
看了一下Excel,数据都有,但是表格格式全部丢失,里边的中文数据全都不见了:
而且,每项数据都给在前边给我加了个',好在加得很规律,可以用替换功能清理掉。
于是我组合上了上述Textract得到的数据,以及之前用img2table得到的空表格,以及之前班级群里得到的学号以及学生的对应表,成功地复原了期中考试的成绩表。
没想到API没用成,竟然另辟蹊径地解决了这个问题,哈哈哈,这次看谁还可以嘲笑我?😡
你可能会问,之前不说不用在线转换程序嘛?好吧,Amazon毕竟大佬(窃取或者泄露信息的概率很低),向大佬低头并不可耻。😳