Hadoop MapReduce
Introduction
Hadoop, un framework open source au sein de la fondation Apache, facilite le traitement distribué de données massives à travers des nœuds répartis sur plusieurs machines. Conçu pour résister aux pannes fréquentes dans de telles structures, Hadoop divise le traitement des données en blocs optimisés.
Le model MapReduce est une spécialisation de la stratégie split-apply-combine pour l'analyse des données. Et il est inspiré par les fonctions map et reduce de la programmation fonctionnelle, même si leur utilisation dans le cadre de MapReduce est différente de leur utilisation originale.
Le modèle algorithmique MapReduce, intégré à Hadoop, divise automatiquement les traitements en tâches indépendantes exécutées en parallèle sur un cluster. Et cela est fait sur trois étapes clés de MapReduce sont Map, Shuffle, et Reduce.
HDFS(Hadoop Distributed File System)
Le Hadoop Distributed File System (HDFS) est un système de fichiers distribué qui gère de grands ensembles de données exécutés sur du matériel standard. Il est utilisé pour faire évoluer un seul cluster Apache Hadoop vers des centaines (voire des milliers) de nœuds. HDFS est l'un des composants majeurs d'Apache Hadoop, avec MapReduce
Map
L'étape Map de Hadoop MapReduce marque le départ du traitement distribué des données massives. Les données préalablement partitionnées sont traitées par des tâches Map, où chaque tâche transforme un ensemble de données en paires clé/valeur de manière indépendante, créant ainsi une base pour le traitement ultérieur.
Cette phase, caractérisée par son indépendance entre les nœuds du cluster, constitue la première étape du modèle "diviser pour régner", permettant une exécution parallèle efficace.
Shuffle
L'étape Shuffle, trie les paires clé/valeur par clé, regroupe les valeurs de différentes machines, formant ainsi des listes de valeurs par clé. Ce regroupement stratégique crée une structure prête à être utilisée dans l'étape Reduce, assurant une transition fluide entre ces deux phases.
Reduce
L'étape finale, ne pourra commencer jusqu'à ce que toutes les tâches Map soient terminées, et elle vise à réduire les données associées à chaque clé. La fonction Reduce peut utiliser divers agrégats (somme, moyenne, etc.) et effectuer des opérations post-réduction.
Vue d'ensemble
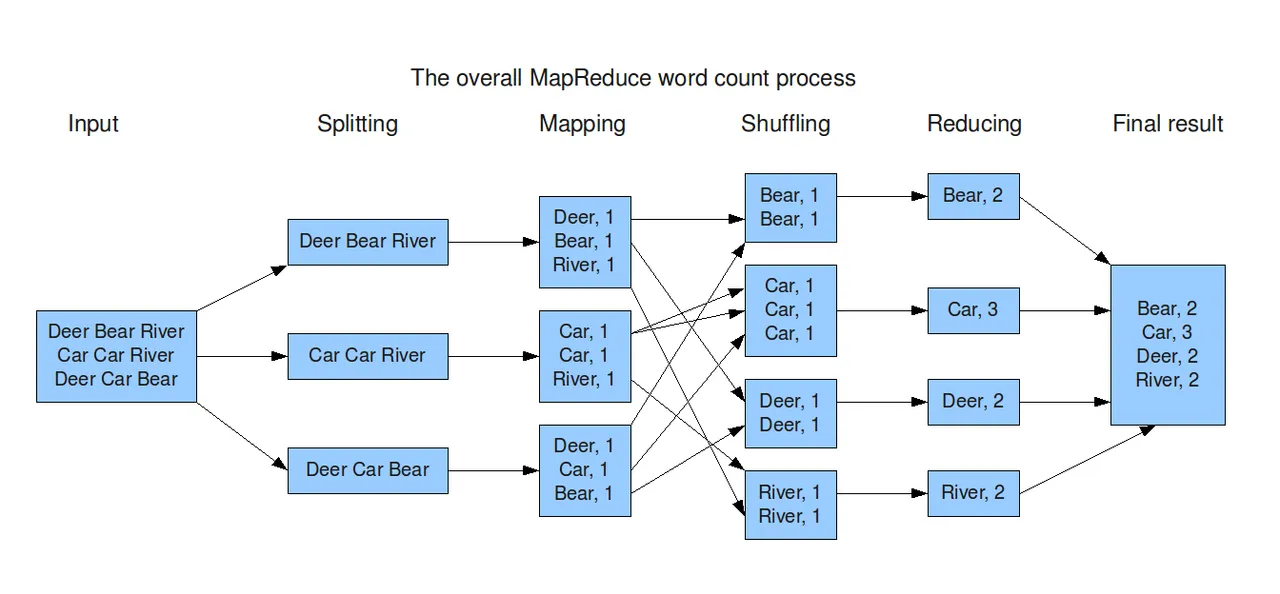
Pendant la phase Map, le traitement est indépendant entre les nœuds. En revanche, pendant la phase Reduce, la communication entre les nœuds via les fichiers peut être lente.
La programmation MapReduce simplifie la tâche de l'utilisateur en gérant l'exécution parallèle et la coordination des tâches dans le cluster.
Conclusion
En somme, Hadoop MapReduce offre une solution robuste pour le traitement distribué de données massives, avec une programmation simplifiée et une coordination efficace dans un cluster Hadoop.