Hadoop MapReduce

La méthode de programmation map reduce de hadoop est une méthode qui permet de synthétiser des données via 2 méthodes principales : Map et Reduce.
Au départ, les données se retrouvent sur les serveurs Hadoop et ce seront justement les algorythmes de map et reduce qui s'exécuteront sur ces serveurs de data. Les données ne devront ainsi pas se déplacer vers un serveur central pour être traitées par ces algorythmes. On obtiens ainsi un gain de temps concidérable.
Principe de Map et Reduce
- La fonction Map transforme les entrées des données du serveurs en paires <clé,valeur>. Il les traite et génère un autre ensemble de paires <clé,valeur> intermédiaires en sortie.
- La fonction Reduce transforme également les entrées en paires <clé,valeur> et génère une des paires <clé,valeur> en sortie.
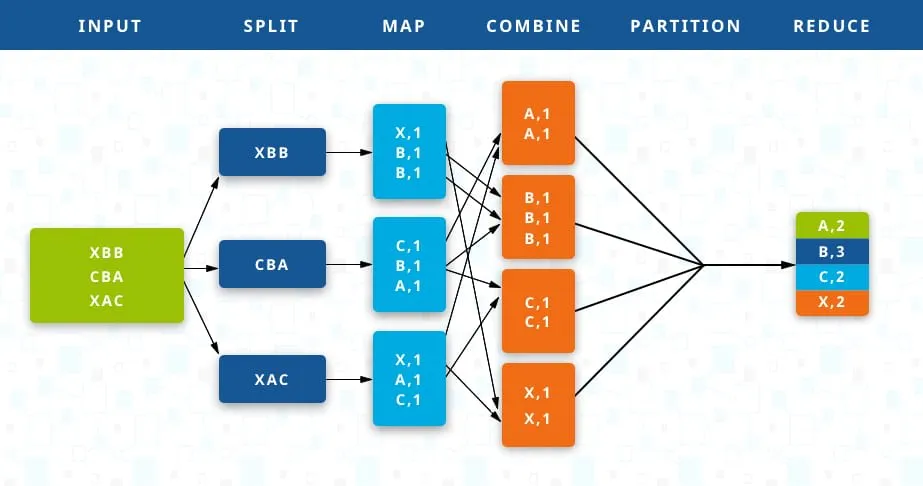
Ces 2 opérations peuvent s'exécuter autant qu'on le souhaite. L'objectif est, qu'à la fin, on obtienne une donnée qui résulte d'une suite d'exécution des méthodes Map et Reduce en fonction des paramètres qu'on lui donne.
Au niveau de la programmation parallèle?
J'ai, dans le passé, expérimenté l'utilisation de ces méthodes en java (Version 8) avec l'API Stream. Sur un processus, ces opérations peuvent s'exécuter sur plusieurs threads en parallèle. De cette manière, on obtiens un temps d'exécution plus rapide quand on travaille sur un grand volume de données.
Pour plus d'informations, voir Qu'est-ce que Hadoop MapReduce?