Hello Friend Hivean
Meet again with Fhutri Nur Risqa @creative1234
Apache Hive adalah sistem data warehouse untuk peringkasan dan analisis data dan untuk query sistem data besar dalam platform Hadoop open-source. Itu mengubah query seperti SQL menjadi pekerjaan MapReduce untuk eksekusi mudah dan pemrosesan volume data yang sangat besar.

Saat ini, Hadoop memiliki hak istimewa untuk menjadi salah satu teknologi paling luas dalam hal mengolah Big Data dalam jumlah besar. Hadoop seperti lautan dengan beragam alat dan teknologi yang secara eksklusif terkait dengannya. Salah satu teknologi tersebut adalah Apache Hive. Apache Hive adalah komponen Hadoop yang biasanya digunakan oleh analis data. Meskipun Babi Apache juga dapat digunakan untuk tujuan yang sama, Hive lebih banyak digunakan oleh peneliti dan pemrogram. Ini adalah sistem pergudangan data sumber terbuka, yang secara eksklusif digunakan untuk menanyakan dan menganalisis kumpulan data besar yang disimpan di Hadoop.

Tiga fungsi penting yang digunakan Hive adalah peringkasan data, analisis data, dan kueri data. Bahasa permintaan, secara eksklusif didukung oleh Hive, adalah HiveQL. Bahasa ini menerjemahkan query seperti SQL ke dalam pekerjaan MapReduce untuk menempatkan mereka di Hadoop. HiveQL juga mendukung skrip MapReduce yang dapat dicolokkan ke kueri. Hive meningkatkan fleksibilitas desain skema dan juga serialisasi data dan deserialisasi.
Hive paling cocok untuk pekerjaan batch, daripada bekerja dengan data log web dan data append-only. Ini tidak dapat berfungsi untuk sistem pemrosesan transaksi online (OLTP) karena tidak menyediakan permintaan waktu nyata untuk pembaruan tingkat baris.
Ingin mempelajari lebih lanjut tentang Hadoop? Lihatlah Tutorial Hadoop Link
Kebanyakan sistem file penting yang didukung oleh Hive adalah:
• File datar atau file teks
• File urutan terdiri dari pasangan kunci-nilai biner
• RCFiles yang menyimpan kolom dari suatu tabel dalam basis data berbentuk kolom
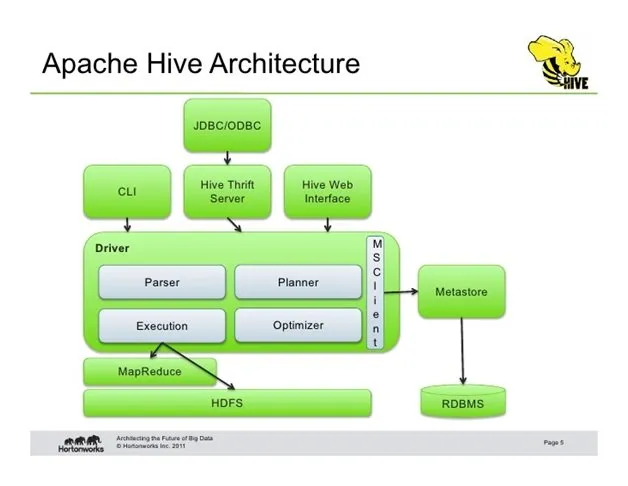
Arsitektur Apache Hive
Komponen Utama Arsitektur Hive*
Metastore: Ini adalah repositori dari metadata. Metadata ini terdiri dari data untuk setiap tabel seperti lokasi dan skema. Ia juga menyimpan informasi untuk metadata partisi yang memungkinkan Anda memantau berbagai data terdistribusi yang berkembang di kluster. Data ini umumnya ada di database relasional. Metadata melacak data, menggandakannya, dan menyediakan cadangan jika terjadi kehilangan data.
Driver: Driver menerima pernyataan HiveQL dan bekerja seperti pengontrol. Ini memantau kemajuan dan siklus hidup berbagai eksekusi dengan membuat sesi. Pengandar menyimpan metadata yang dihasilkan saat menjalankan pernyataan HiveQL. Ketika operasi pengurangan selesai oleh pekerjaan MapReduce, driver mengumpulkan poin data dan hasil kueri.
Compiler: Compiler ditugaskan dengan tugas mengubah permintaan HiveQL menjadi input MapReduce. Ini termasuk metode untuk menjalankan langkah-langkah dan tugas yang diperlukan untuk membiarkan output HiveQL seperti yang dibutuhkan oleh MapReduce.
Pengoptimal: Ini melakukan berbagai langkah transformasi untuk agregasi dan konversi jalur pipa dengan satu gabungan untuk beberapa gabungan. Itu juga ditugaskan untuk membagi tugas sambil mengubah data, sebelum mengurangi operasi, untuk meningkatkan efisiensi dan skalabilitas.
Pelaksana: Pelaksana menjalankan tugas setelah tahap kompilasi dan optimisasi. Ini langsung berinteraksi dengan Pelacak Pekerjaan Hadoop untuk menjadwalkan tugas yang akan dijalankan.
CLI, UI, dan Thrift Server: Antarmuka baris perintah (CLI) dan antarmuka pengguna (UI) mengirimkan permintaan dan proses pemantauan dan instruksi sehingga pengguna eksternal dapat berinteraksi dengan Hive. Thrift Server memungkinkan klien lain berinteraksi dengan Hive.
Jika Anda memiliki pertanyaan apa pun yang terkait dengan Apache Hive, letakkan di komunitas dan lakukan klarifikasi dalam sehari!.
Memahami HiveQL
Bahasa query yang digunakan dalam Apache Hive disebut HiveQL, tetapi itu bukan bahasa query terstruktur (SQL). Namun, HiveQL menawarkan berbagai ekstensi lain yang bukan bagian dari SQL. Dimungkinkan untuk memiliki properti ACID penuh di HiveQL, bersama dengan pembaruan, masukkan, dan hapus fungsi. Anda dapat melakukan sisipan multi-tabel dan menggunakan sintaksis seperti 'buat tabel sebagai pilih' dan 'buat tabel seperti' di HiveQL, tetapi hanya memiliki dukungan dasar untuk indeks. HiveQL tidak memberikan dukungan untuk pemrosesan transaksi online dan melihat materialisasi. Ini hanya menawarkan dukungan sub-permintaan.
Cara Hive menyimpan dan menanyakan data sangat mirip dengan database biasa. Tetapi karena Hive dibangun di atas ekosistem Hadoop, Hive harus mematuhi aturan yang ditetapkan oleh kerangka kerja Hadoop.
Lihatlah bagian atas Link untuk mendapatkan pekerjaan bergaji tinggi!.
Mengapa menggunakan Apache Hive?
Apache Hive terutama digunakan untuk query data, analisis, dan peringkasan. Ini membantu meningkatkan produktivitas pengembang yang biasanya datang dengan biaya meningkatkan latensi. Hive adalah varian dari SQL dan memang sangat bagus. Itu berdiri tinggi jika dibandingkan dengan sistem SQL yang diimplementasikan dalam database. Hive memiliki banyak fungsi yang ditentukan pengguna yang menawarkan cara efektif untuk menyelesaikan masalah. Sangat mudah untuk menghubungkan permintaan Hive ke berbagai paket Hadoop seperti RHive, RHipe, dan bahkan Apache Mahout. Selain itu, sangat membantu komunitas pengembang bekerja dengan pemrosesan analitis yang kompleks dan format data yang menantang.
Data warehouse mengacu pada sistem yang digunakan untuk pelaporan dan analisis data. Apa artinya ini adalah memeriksa, membersihkan, mentransformasikan, dan memodelkan data dengan tujuan menemukan informasi yang berguna dan menyarankan kesimpulan. Analisis data memiliki banyak aspek dan pendekatan, mencakup beragam teknik di bawah berbagai nama dalam domain yang berbeda.
Hive memungkinkan pengguna mengakses data secara bersamaan dan, pada saat yang sama, meningkatkan waktu respons, mis., Waktu yang dibutuhkan sistem atau unit fungsional untuk bereaksi terhadap input yang diberikan. Bahkan, Hive biasanya memiliki waktu respons yang jauh lebih cepat daripada kebanyakan tipe kueri lainnya. Hive juga sangat fleksibel karena lebih banyak komoditas dapat dengan mudah ditambahkan sebagai tanggapan terhadap penambahan lebih banyak kelompok data tanpa penurunan kinerja.
Siapa audiens yang tepat untuk mempelajari teknologi ini?
Pengembang, Administrator Sistem, dan Hadoop Analytics, Administrasi, Data Warehousing, dan SQL Professionals.
Apa kelebihan belajar Hive?
Apache Hive memungkinkan Anda bekerja dengan Hadoop dengan cara yang sangat efisien. Ini adalah infrastruktur gudang data lengkap yang dibangun di atas kerangka kerja Hadoop. Hive dikerahkan secara unik untuk menghasilkan kueri data, analisis data yang kuat, dan peringkasan data saat bekerja dengan volume data yang besar. Bagian integral dari Hive adalah HiveQL yang merupakan antarmuka seperti SQL yang digunakan secara luas untuk meminta data yang disimpan dalam database.
Hive memiliki keuntungan berbeda dalam menggunakan data berkecepatan tinggi untuk membaca dan menulis di dalam gudang data sambil mengelola kumpulan data besar yang didistribusikan di beberapa lokasi, semuanya berkat fitur-fiturnya seperti SQL. Hive menyediakan struktur untuk data yang sudah disimpan dalam database. Pengguna dapat terhubung dengan Hive menggunakan alat baris perintah dan driver JDBC.
Bagaimana Hive akan membantu Anda dalam karier Anda?
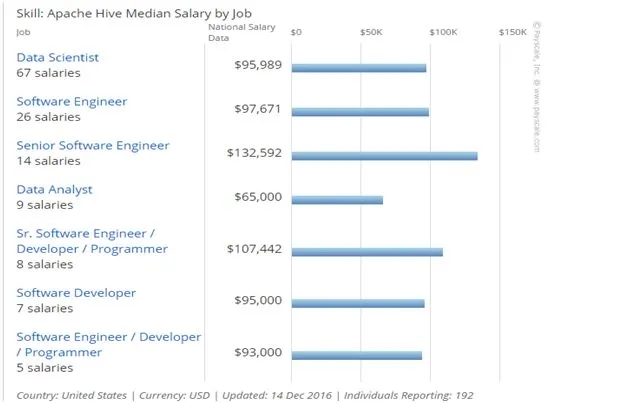
Apache Hive adalah keterampilan yang sangat dicari untuk dikuasai jika Anda ingin menjadi besar di dunia Big Data Hadoop. Saat ini, sebagian besar perusahaan mencari orang-orang dengan keterampilan yang tepat ketika datang untuk menganalisis dan menanyakan volume data yang besar. Dengan demikian, mempelajari Apache Hive adalah cara terbaik untuk mendapatkan gaji tertinggi di beberapa organisasi terbaik di seluruh dunia.
Hubungi Intellipaat dan daftar di Link luar biasa untuk membawa karier Anda.
Nah, teman-teman semua! Setelah saya baca beberapa artikel tentang Apache Hive, lalu saya terjemah kedalam bahasa Indonesia lalu saya jadikan postingan di blog saya.
Kenapa, Karena saya tidak tahun harus membuat postingan yang bagus, baik, benar dan disukai oleh komunitas Hive.
Salam, Jangan Pernah Menyerah