Here's a detailed update on last week's work for hardfork 24. Be warned that a lot of this will sound like complete gibberish unless you're a programmer :-)
Hived (core blockchain code)
At this point, we think we’ve made all the changes necessary on the hived side to support hivemind in this release. A good indicator for this is we only needed to merge in one update in the last week for hived:
https://gitlab.syncad.com/hive/hive/-/merge_requests/91
We can’t be 100% sure yet, as we still have a decent number of hivemind tests that are failing, but if those clear up in the next couple of days, we can probably tag a release candidate for hived this week.
If we do get out a release candidate this week, we’ll set the hardfork date for 3 weeks from the day the release candidate is available. That should provide more than sufficient time for all the 2nd layer apps to be tested fully, given there are few changes at the API level that will impact existing applications.
Hivemind (2nd layer social media microservice)
Most of this week was spent improving the automated testing system and fixing bugs in Hivemind.
A week of hivemind bug fixes
In total, we had about 10 commits to fix hivemind bugs this week. One of the bugs that we fixed was reported by @asgarth in the experimental version of hivemind that we’re currently running on our production system at api.hive.blog. It resulted in pinned posts showing up more than once in some communities on peakd.com.
The bug was kind of interesting, because it showed up in peakd, but not on hive.blog, so we hadn’t previously detected it during our manual testing. This is another reason it’ll be nice once we have more automated tests available for hivemind, since they are much more likely to spot these types of code regressions.
Implemented tavern-based testing system for hivemind
Today we finished updating the automated testing system using the tavern framework that I mentioned last week. Tavern allows us to mark tests as “allowed to fail” and also allows us to see which individual tests failed and why. This makes it much easier for us to quickly identify problem tests and even quickly see why they failed. It also helps us in judging our progress in fixing bugs, since we have a clear history of what’s passing and what’s failing after each code change. Here’s what the new tavern test display looks like hivemind:
https://gitlab.syncad.com/hive/hivemind/pipelines/15579/test_report
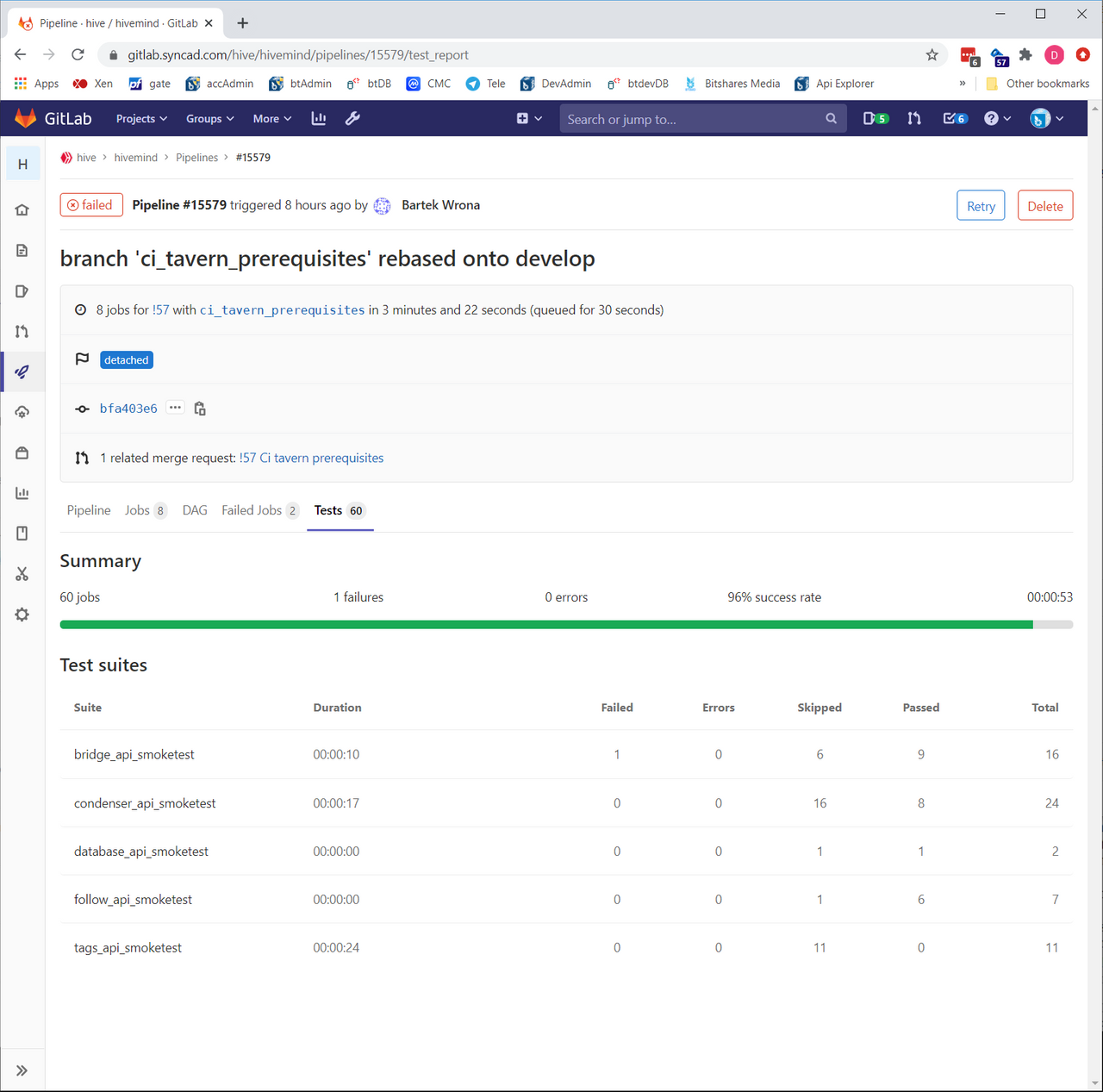
In the first test set (bridge_api_smoketest), we had 9 tests that passed, 6 that were skipped (expected failures), and one unexpected fail.
We can also click on this test set, to drill in and see which tests passed, failed, or were skipped. The first 6 tests are the expected fails. For the failing test (get_profile, the one at the bottom of the screenshot), we can see a traceback of why it failed:
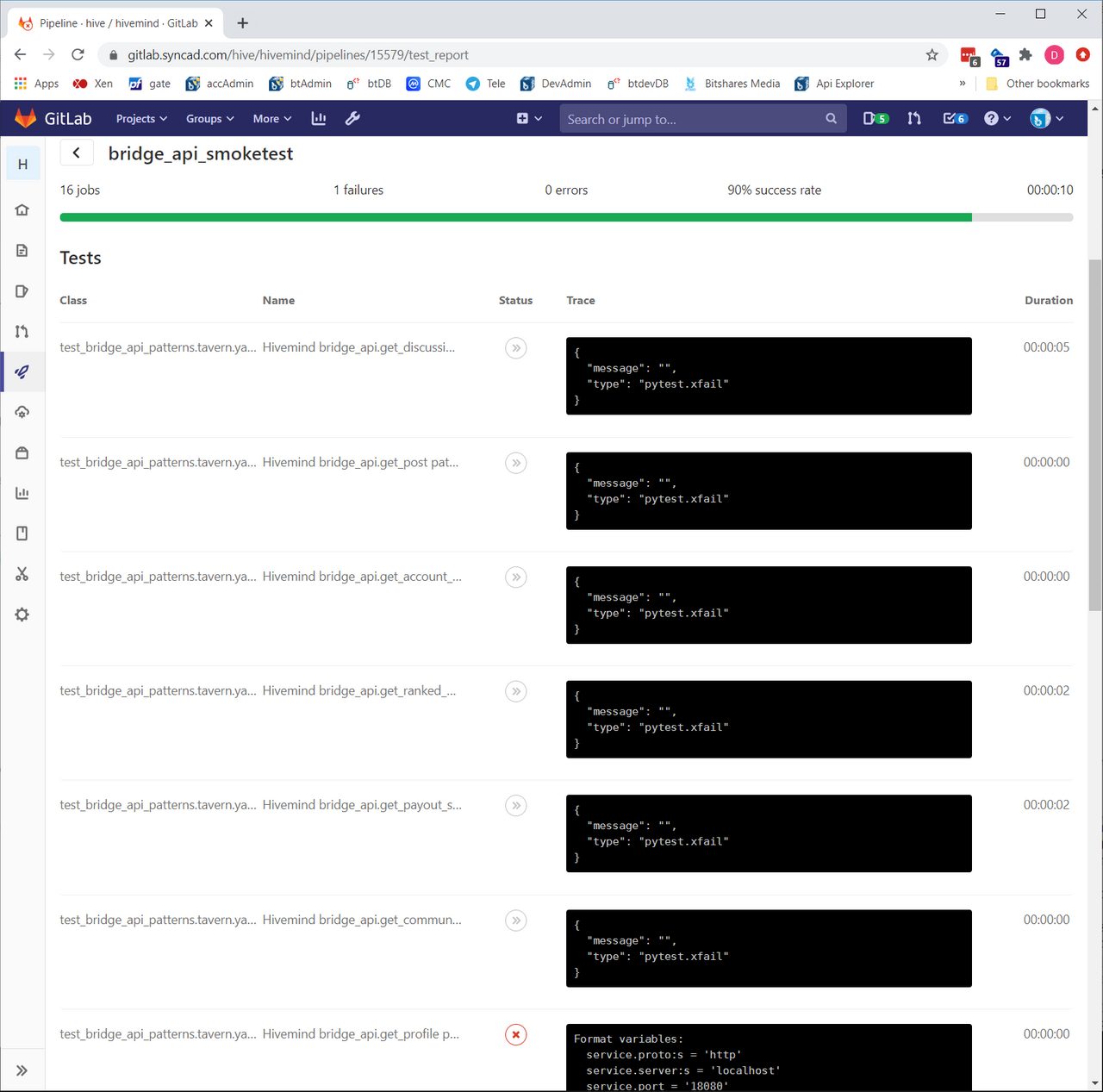
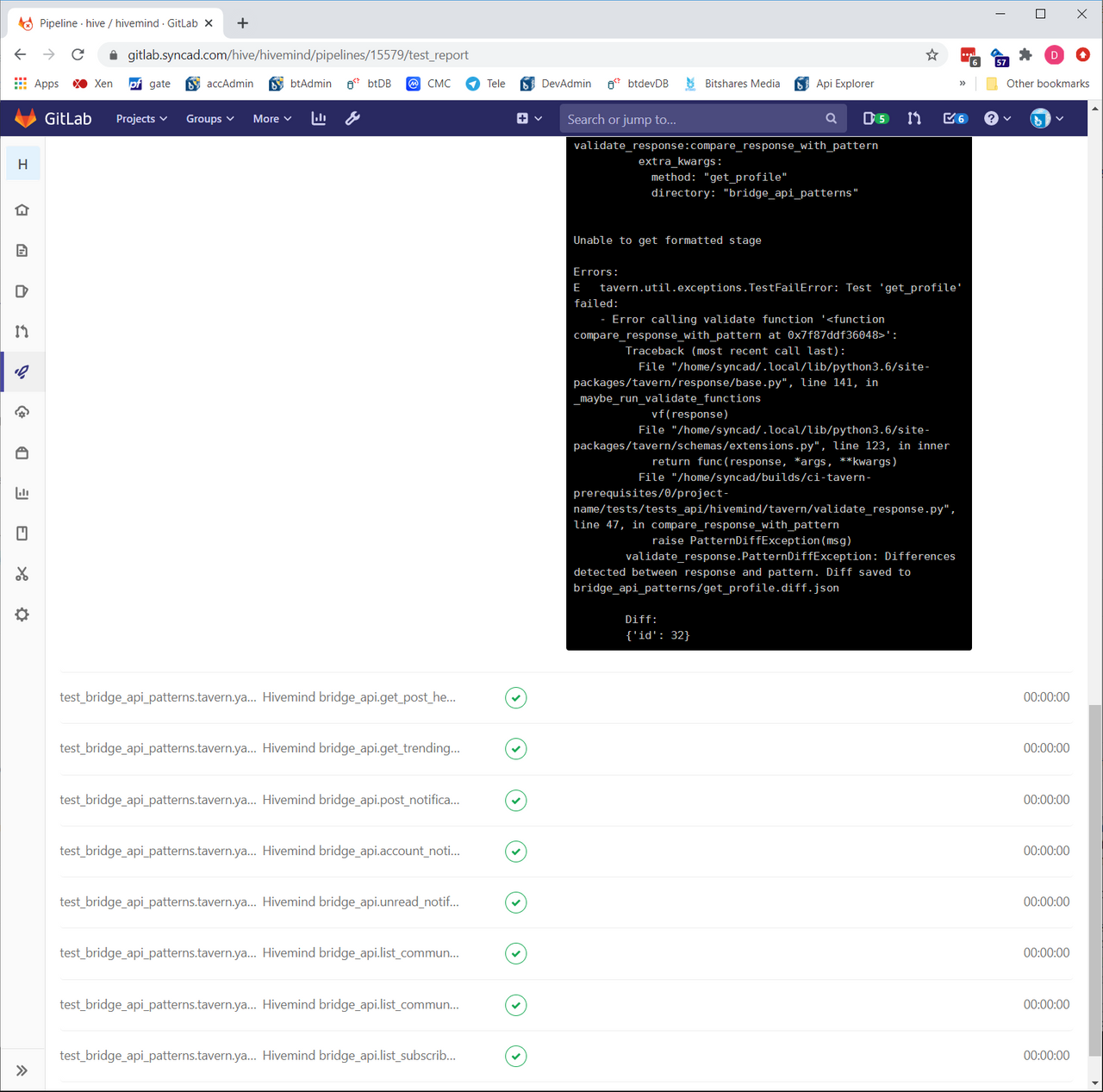
We just got tavern running today, so it’ll be interesting to see how it helps out in our upcoming work this week.
Recent slow down in a SQL query points to need for performance tests for hivemind
One of our ideas for “code cleanup” fixes in hivemind was to use views to replace some joins in multiple SQL queries as a code refactoring technique but this resulted in a significant slowdown in one of our hivemind queries. It appears that the SQL optimizer in postgres is generating a bad plan in such cases.
We had previously optimized this query to take 20ms in the test case, and after the change it took 20s! We were able to run ANALYZE to update the database statistics for the planner and get its performance up to 60ms, but that’s still 3x worse than our original optimized version, so it’s really not acceptable. We’re going to see if this problem was addressed in later versions of postgres (we’re running 10 now, we’re going to try upgrading to 12 and see if that helps), but if that fails we’ll revert back to inlining the joins as per our original optimized version of this query for now, since we don't want to spend too much time on this problem now.
One lesson we’ve learned several times is that it is very easy to damage performance if you’re not super careful in how you structure your queries. A lot of the work we did on hivemind was to optimize these queries, and those optimizations can easily be broken by seemingly innocuous changes like the one mentioned above, so it’s clear we’re really going to need performance tests for hivemind as well as functional tests.
Originally I’d been hoping we could make do with the performance numbers we get from real-time Jussi logs on production systems to serve as a reality check on hivemind performance, but at this point I think this kind of performance testing needs to be done in our automated tests, so that we can detect a performance problem as soon as it occurs.
Condenser (source code for hive.blog)
We mostly finished up the work related to decentralized lists this week, and it can potentially be deployed before the hardfork, since it only requires changes to hivemind, not to hived, but my gut feeling is we should wait until all the eclipse code is ready, since a roll out before HF24 would mean that node operators would need to resync their hivemind databases twice (once for decentralized lists, then again for HF24). All-in-all, I think it’s better to wait. One thing we could do is maybe roll it out on the staging version of condenser, which would allow the curious to start trying it out now.
We’re also finishing up a feature to allow users to pick their own API nodes for hive.blog. Currently condenser allows you to select from an existing set of API nodes, but the new feature will allow you to use any node, not just ones from the existing set.
Another improvement to condenser: @quochuy widened the space for posts, as there was a lot of wasted margin space previously.
Summary of work and expectations for next week
Hivemind work is consuming most of our time at this point. We’ve fixed a lot of bugs this week, and we’ve finally got the testing system for it where we want it to be, so we made good progress, but there’s certainly been more problems with Hivemind that we hoped.
I’m still hoping we can make a hived release candidate in the next couple of days, and finding only one bug last week was pretty reassuring, but it’s definitely not a sure thing yet. It’s a little harder to predict on hivemind’s timeline, but some time next week seems feasible.