About a month ago I wrote my first Python script that had a purpose.
This is the second. Actually, in-between I wrote a small script which allowed me to follow a curation trail (something one can easily do with tools like steemauto / hive.vote), but I just wanted to play with the necessary APIs myself.
Some time ago I read a comment or a post, I can't remember of whom, where the author said he might replace "steemit.com" URLs with "peakd.com".
That got me thinking at the time. How would I do it, if I wanted to?
From the SEO perspective, having more back links to your domain is beneficial.
Being the flagship interface of Steem for a long time, steemit.com obviously got a lot of these back links, many of them from people now on Hive.
A win-win solution to this problem was implemented by PeakD, where all previous links are displayed as peakd.com links on their interface, but there is a link at the bottom to the original post, for pre-hardfork posts.
This solution has the advantage of not requiring any implication from its users, and it also doesn't completely cut off the original source app, because there is a link to it at the bottom.
The drawbacks are that the links specific to each interface will be broken and this solution is also implemented only in PeakD (possibly in other interfaces where I haven't checked).
So, using my Python script you'll be able to find URLs in your posts matching diverse criteria like:
- pattern matching (regex)
- exact match / exact beginning flags
- filtered by date and time
- filtered by app used to create the post
- filtered by post number
- filtered by author
- filtered by blockchain (Hive or Steem)
Additionally, I often start from one point and realize I can build on it.
This is what happened here.
I thought, while I find these URL matches (which can also match all URLs, by the way), why not build a feature to test them if they are OK or broken?
So, there is the option to test for broken links.
Some bullet points here:
- test matching regular links, images or both
- building up a list with previously tested links, so that the same link won't be tested twice
- possibility to use a domain exclusion list from testing, with reason to do so which will be included in the results instead of the test result, after the mention that the link was not tested
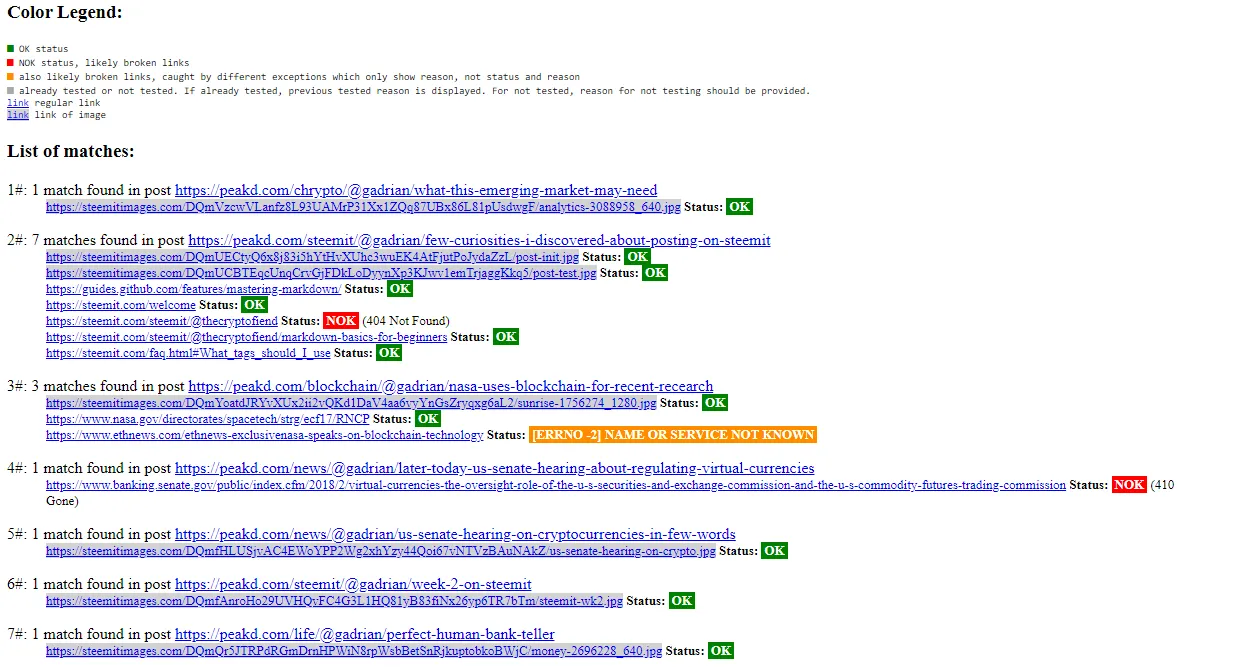
Results are outputted using print and in either of these two formats
- html, in pretty form, for manual review
- text, likely to be used by a script at a later time (for example to auto-replace matches)
Both file outputs use line numbering, in case one wants to manually remove entries from the text output before feeding it to a script.
For now I haven't written an auto-replace script. One reason for that is that I don't think a bulk replace would be great. It's better to take them one by one and see what needs to be replaced, if any.
But I think the URL checker can reveal some interesting results about broken links, broken or abandoned apps and possibly more.
The URL checker is not perfect, it will sometimes show errors where normal browsing won't. Most common ones, like Pixabay, have been treated as exceptions. But it's better to check a link identified to have issues manually by clicking on it to make sure it's not just the server 'not liking' our script checking on the status of the page.
Partial URLs, like the ones without protocol or more specific, permalink without interface domain are identified as OK if they are OK when 'http(s)' protocol is added or the default interface URL. This is normal, because that will happen when you browse on your favorite interface. But if you click on the link that is in the results, the browser will not recognize the URL and you'll have to 'complete' the link yourself.
Example: peakd.com will test OK, but if you click on the link on the results, you'll need to add https:// manually to make it work, like this: https://peakd.com.
For who has the patience to fix them, broken links are detrimental to search engine rankings. There is of course the option to hire someone to do it. Especially important to make sure they are correct in cornerstone content!
I published the code on GitHub for anyone interested. There are plenty of comments for new programmers and more instructions on the GitHub about the requirements and how to use it.
https://github.com/gadrian78/find-test-urls-in-hive-steem-posts