It's been a while since I've worked on CoinZdense. More than two months because of personal circumstances. My mariage has been falling apart leading to a semi-homeless status for me in the last few months where I had to often crash at my mom's. At the same time, a new relationship that I put all of my heart into has turned rather complicated in a way that I've found emotionally even harder to handle than the colapse of my mariage and my living conditions.
The last two days I've managed to regain some focus, and while it took me some effort to get back into it, I'm setting out to try and spent at least one whole work day on the project each week.
In this post I want to talk a little bit about an interesting bit about some new code I was working on these last two days.
Before I was forced to pause my efforts on the project, two months ago and a bit, I was reworking the API for the Python version of coinZdense. I've moved the old API to unstable because things overt there kept moving and I wanted to start buikding some tools on top of coinZdense-Python, like the HIVE CoinZdense Disaster Recovery tools that I talked about in this post.
The old API remains available for now, but with a difference in how things are imported. For example:
from coinzdense.app import BlockChainEnv
from coinzdense.fs import EtcEnv
becomes:
from coinzdense.unstable.app import BlockChainEnv
from coinzdense.unstable.fs import EtcEnv
Bit by bit I'm moving functionality from unstable to a part of the API that I intend to keep backward compatible stable. So far, everything in stable has been the layer zero stuff that I needed for building the HIVE CoinZdense Disaster Recovery tools.
A coinZdense signing key consists of a small stack of level keys, where every level key consists of a tree of one-time signing keys. The one-time siging keys get used up with usage, and with them, at some point, so do some of the level keys. When a level key gets exausted, the generation of a new level key is quite CPU intensive, and as such, the time needed to sign a single transaction might go up, one signature in many, from significantly less than a second to multiple minutes, and that is something that from a user perspective isn't a consistent user experience. So the idea is that for user exerience, level-keys need to be generated in the background while the user isn't doing anything in particular.
Yesterday and today I've been working on the API hooks for that at the lowest level, the one-time signing keys.
Working on this subject, I ran into a well known problem with concurency in Python: The GIL or Global Interpreter lock. In short, in most other languages, to speed up the performance of one time signing key creation, the use of threaths would be the obvious choiche. In Python though, in CPU intensive operations not handled by truly GIL-aware libraries like numpy, chances are adding more threads will make CPU intensive tasks slower instead of faster. The coinZdense domain isn't exactly a great fit for numpy, so I started looking at multi process as a option.
A really nice abstraction in Python is provided by the ProcessPoolExecutor in concurent.futures. There is also a ThreadPoolExecutor with the same interface, so I decided to use the Executor as a hook into my API.
I wanted to test the new API extensions, but I also wanted to benchmark them a bit, so I wrote a tiny benchmark script. In this post I want to walk throug that script to show a bit of the API extension so far.
In the future the user won't be exposed to this part of the API at this level as the user normally would use higher level key abstractions that will get a slightly different API, that will abstract away most of the background work in the Wen3 layer, the Web-3.0 Entropy layer that will implement entropy-as-a-resource management and sub-key management.
But now for the low level API. In our script we start off with the imports.
import asyncio
import time
from libnacl import crypto_kdf_derive_from_key as _nacl2_key_derive
from coinzdense.layerzero.onetime import OneTimeSigningKey
from coinzdense.layerzero.wif import key_from_creds
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
The important ones are the imports from coinzdense and from concurrent. We import the OneTimeSigningKey and the key_from_creds function from coinzdense. We import the two types of Executor, so we can show the GIL problem. And finaly we import a function from libnacl that in the future is going to be abstracted away by the level key.
The rest of the code looks like this:
print("reference, no executor")
key = key_from_creds("coinzdense", "demodemo","secretpassword12345")
otsk = []
start = time.time()
for index in range(0,1024):
salt = _nacl2_key_derive(20, index, "levelslt", key)
otsk.append(OneTimeSigningKey(20, 7, salt, key, 1000000*index))
otsk[-1].get_pubkey()
reference = time.time() - start
print(" done, reference =", int(reference),"sec")
for workers in [1,2,3,4]:
for usethreads in [False, True]:
print("workers =", workers, "use threads =", usethreads)
if usethreads:
executor = ThreadPoolExecutor(max_workers=workers)
else:
executor = ProcessPoolExecutor(max_workers=workers)
otsk = []
start = time.time()
for index in range(0,1024):
salt = _nacl2_key_derive(20, index, "levelslt", key)
otsk.append(OneTimeSigningKey(20, 7, salt, key, 1000000*index))
otsk[-1].announce(executor)
cnt = 0
for index in range(0,1024):
while not await otsk[index].available():
cnt += 1
await asyncio.sleep(0.1)
measurement = time.time() - start
print(" done", int(100*measurement/reference),"%")
The first thing the script does is create a master key using the key_from_creds function. Then that master key is used to create the equivalent of the level-key salt, after what both are used to create 1024 one time signing keys with 7 bit OTS chains and 20 byte long blake2 hashes.
The first part of the script uses the synchonous get_pubkey method. OneTimeSigningKey is lazy. On construction the public key isn't calculated yet. But when the pubkey is requested and it hasn't been requested before, the CPU intensive operation is run at that moment. This was already part of the API before. As we see in the script, we use this first run to set ourselves a reference time to measure other outcomes against.
Now we get to the core of the script. A double for loop that tries out each of the two Executor types with 1, 2, 3 and four workers.
We notice the extensions to the API that allow us to use the Executor.
for index in range(0,1024):
salt = _nacl2_key_derive(20, index, "levelslt", key)
otsk.append(OneTimeSigningKey(20, 7, salt, key, 1000000*index))
otsk[-1].announce(executor)
The announce method will queue the calculation of the public key onto the executor. We basicly start calculation in the background. We do this for each of the 1024 one time signing keys.
The next bit of code we wait for all of queued tasks to complete
for index in range(0,1024):
while not await otsk[index].available():
cnt += 1
await asyncio.sleep(0.1)
The async method available returns a boolean indicating that the one time key has completed calculating the public key. Available returns without delay with a True or a False.
Alternatively, the async require method will resolve after the pubkey has been calculated.
So now for the output of the script:
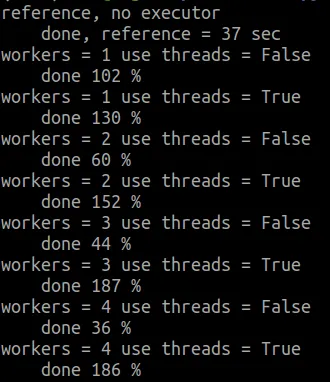
Notice what happens? Let's put it into a table
| workers | ProcessPoolExecutor | ThreadPoolExecutor |
|---|---|---|
| 1 | 102% | 130% |
| 2 | 60% | 152% |
| 3 | 44% | 187% |
| 4 | 36% | 186% |
There is a tiny for using a single process worker, and a moderate overhead for using a single tread worker. But look at what happens when we scale up. Multi processing makes things speed up, as intended while multi thread makes things slow down. This demonstrates the problems withe Python and the GIL for CPU intensive tasks.
When later on we continue with the C++ version of CoinZdense, the code will undoubtedly use threaths rather than processes, but ont so for Python.
The next step right now is to start working on integrating the use of this API into the level key code and migrating the resulting code to the stable API as soon as possible. But that is for next time.
Getting back into the project again is taking some effort, but there is progress again and that is most important right now.
Support the CoinZdense project
As I mentioned in my talk at HiveFest, CoinZdense is a one-man and unfunded project. You can help support the project by buying project support tokens on hive-engine, by helping out looking at the 1995 style project website, or by advocating with the different target Web3 ecosystem communities.
So far the project has received roughly 33 HBD from sale of project support tokens on hive-engine, from a tiny Paypal donation on the tipping-jar page, and from post upvotes.