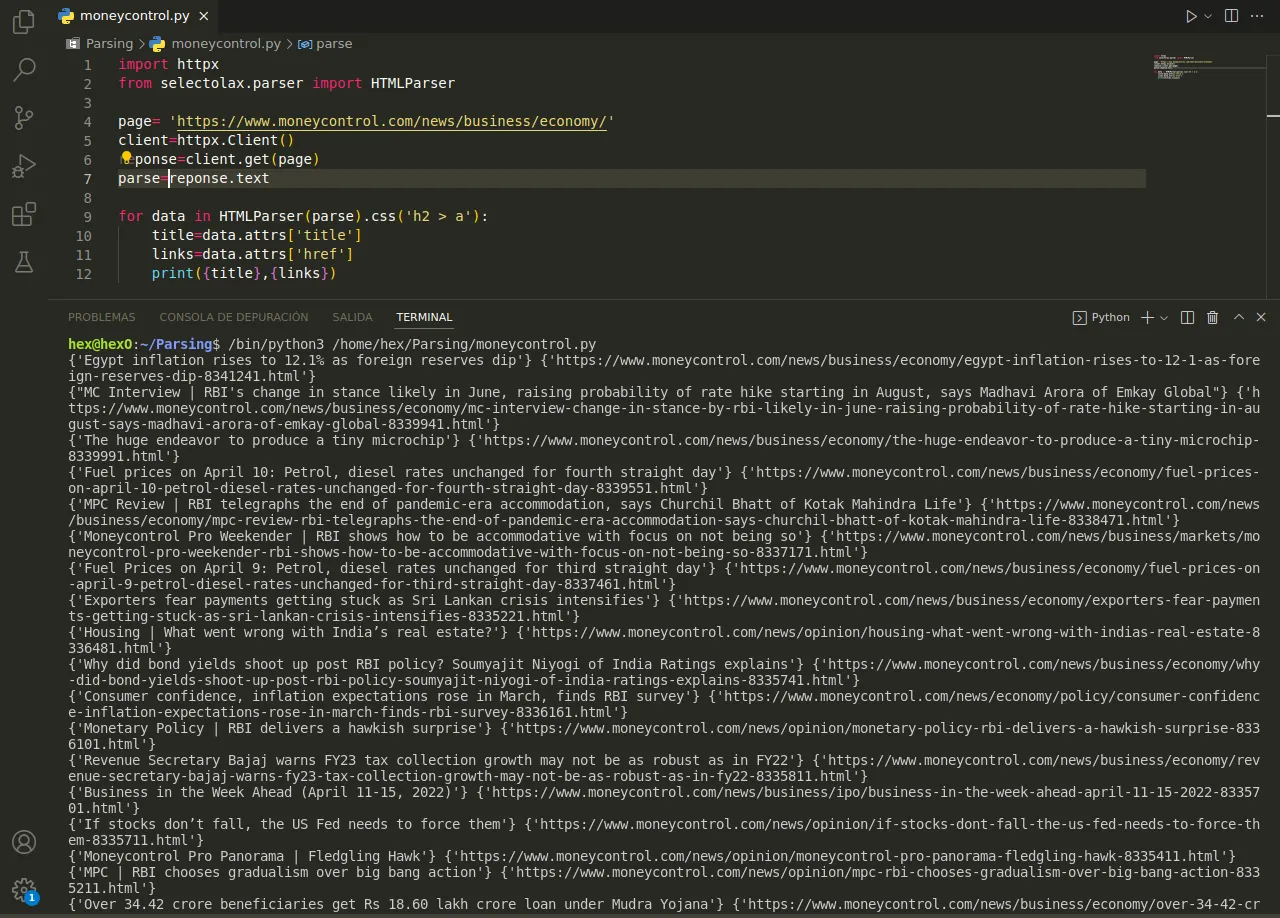
Saludos hivers. les presto un script para obtener noticias del sitio web https://www.moneycontrol.com/ un sitio financiero creado en 1999 que ofrece información sobre economía y finanzas, tiene una sección para realizar inversiones, análisis de datos, herramientas financieras y monitorear las finanzas corporativas y personales.
Para extraer más titulares y enlaces de este sitio web debe de agregar al final de la URL /page-2/ la URL quedará estructurada de la siguiente manera: https://www.moneycontrol.com/news/business/economy/page-2/ en /page-/ debe de reemplazarlo por el número de la página de la que usted quiera obtener los enlaces.
Les dejo el script, espero que esta herramienta sea provechosa para ustedes. Hasta la próxima.
Greetings hivers. I lend you a script to get news from the web site https://www.moneycontrol.com/ a financial site created in 1999 that offers information on economics and finance. financial site created in 1999 that offers information about economy and finance, it has a section to make investments, data analysis, financial tools and monitor corporate and personal finance.
To extract more headlines and links from this website you must add at the end of the URL /page-2/ the URL will be structured as follows: https://www.moneycontrol.com/news/business/economy/page-2/ in /page-/ you must replace it with the number of the page you want to get the links.
I leave you to the script I hope this tool will be useful for you. See you next time.
import httpx
from selectolax.parser import HTMLParser
page= 'https://www.moneycontrol.com/news/business/economy/'
client=httpx.Client()
reponse=client.get(page)
parse=reponse.text
for data in HTMLParser(parse).css('h2 > a'):
title=data.attrs['title']
links=data.attrs['href']
print({title},{links})