Saludo hivers. Les presento un nuevo script para usarlo en el sitio web dataconomy. Que no es más que otros sitios populares que se encarga de mantenernos informados sobre fintech y ciencia de datos. Dispone información sobre eventos y trabajos de investigación.
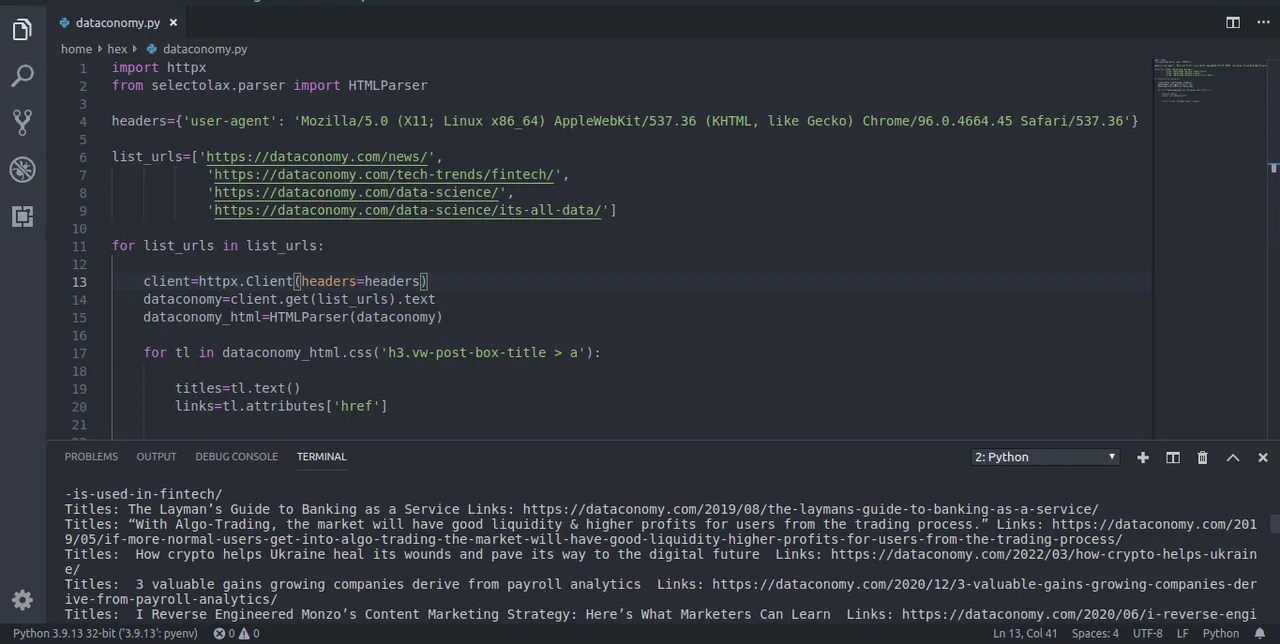
El funcionamiento de este script consiste en navegar y extraer en diferentes tópicos los datos tal y como se titula esta publicación. El resultado final será la obtención de títulos y enlaces de múltiples páginas.
Si está interesado en escribir sobre ciencia de datos, en este sitio web puedes comunicarte con los administradores para que atiendan tu solicitud.
Bueno, no tengo mucho que agregar. Pronto estaré dejando de publicar sobre webscripting y me centraré nuevamente en escribir artículos relacionados con la economía, la ecología y programación en análisis de datos utilizando Python.
Gracias por tomar su tiempo en esta pequeña lectura. Espero que vuelva pronto.
Este script fue ejecutado con Python 3.9.13 en el sistema operativo Lubuntu 18.0.4.
Greetings hivers. I present you a new script to use in dataconomy website. Which is nothing more than other popular sites that is in charge of keeping us informed about fintech and data science. It has information about events and research papers.
The operation of this script is to browse and extract in different topics the data as titled in this post. The end result will be titles and links to multiple pages.
If you are interested in writing about data science, on this website you can contact the administrators to take care of your request.
Well, I don't have much to add. Soon I will be stopping posting about webscripting and will be focusing again on writing articles related to economics, ecology and programming in data analysis using Python.
Thanks for taking your time in this little reading. I hope you will come back soon.
This script was executed with Python 3.9.13 on Lubuntu 18.0.4 operating system.
import httpx from selectolax.parser import HTMLParserheaders={'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'}
list_urls=['https://dataconomy.com/news/',
'https://dataconomy.com/tech-trends/fintech/',
'https://dataconomy.com/data-science/',
'https://dataconomy.com/data-science/its-all-data/']for list_urls in list_urls:
client=httpx.Client(headers=headers) dataconomy=client.get(list_urls).text dataconomy_html=HTMLParser(dataconomy) for tl in dataconomy_html.css('h3.vw-post-box-title > a'): titles=tl.text() links=tl.attributes['href'] print(f'Titles: {titles} Links: {links}')