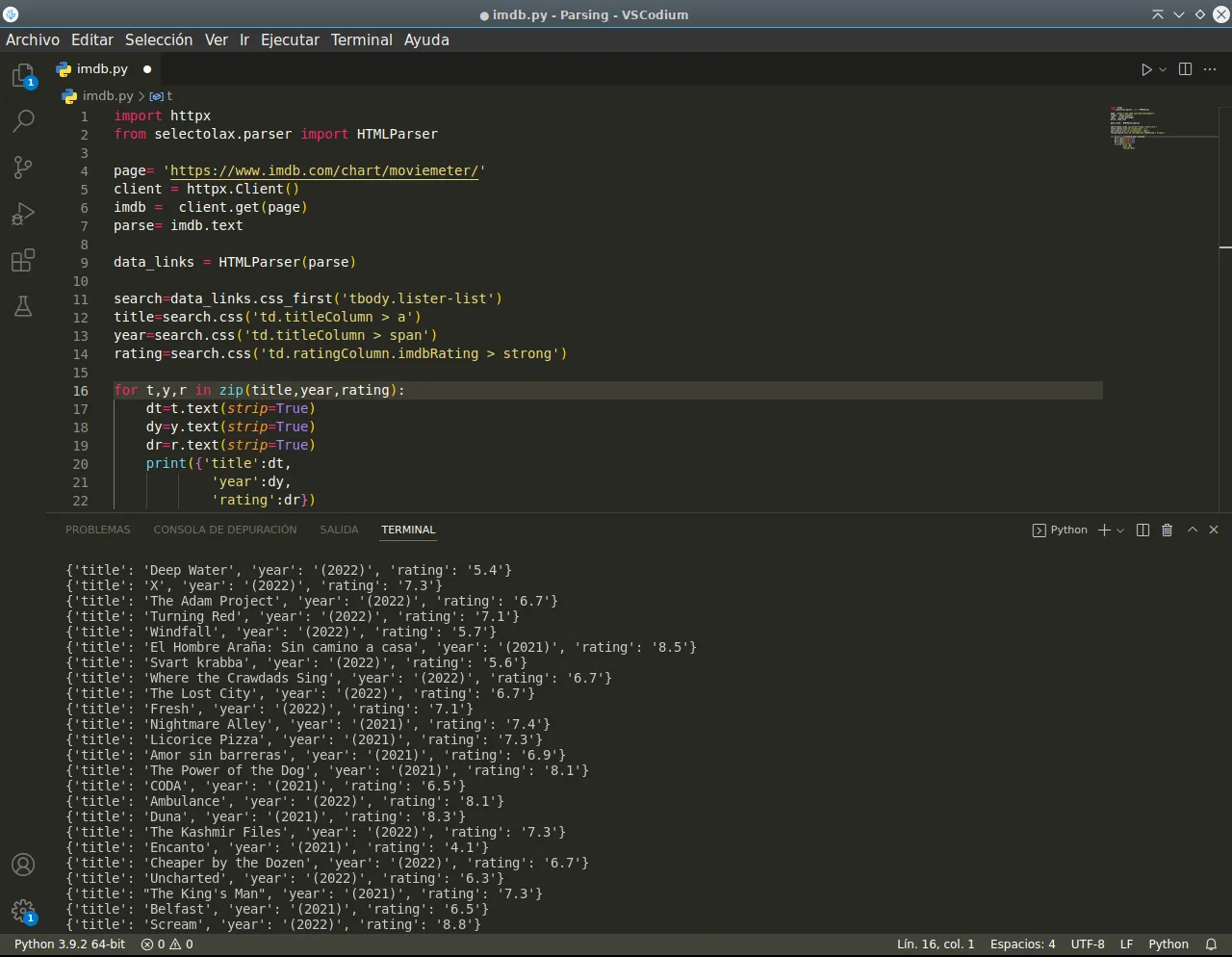
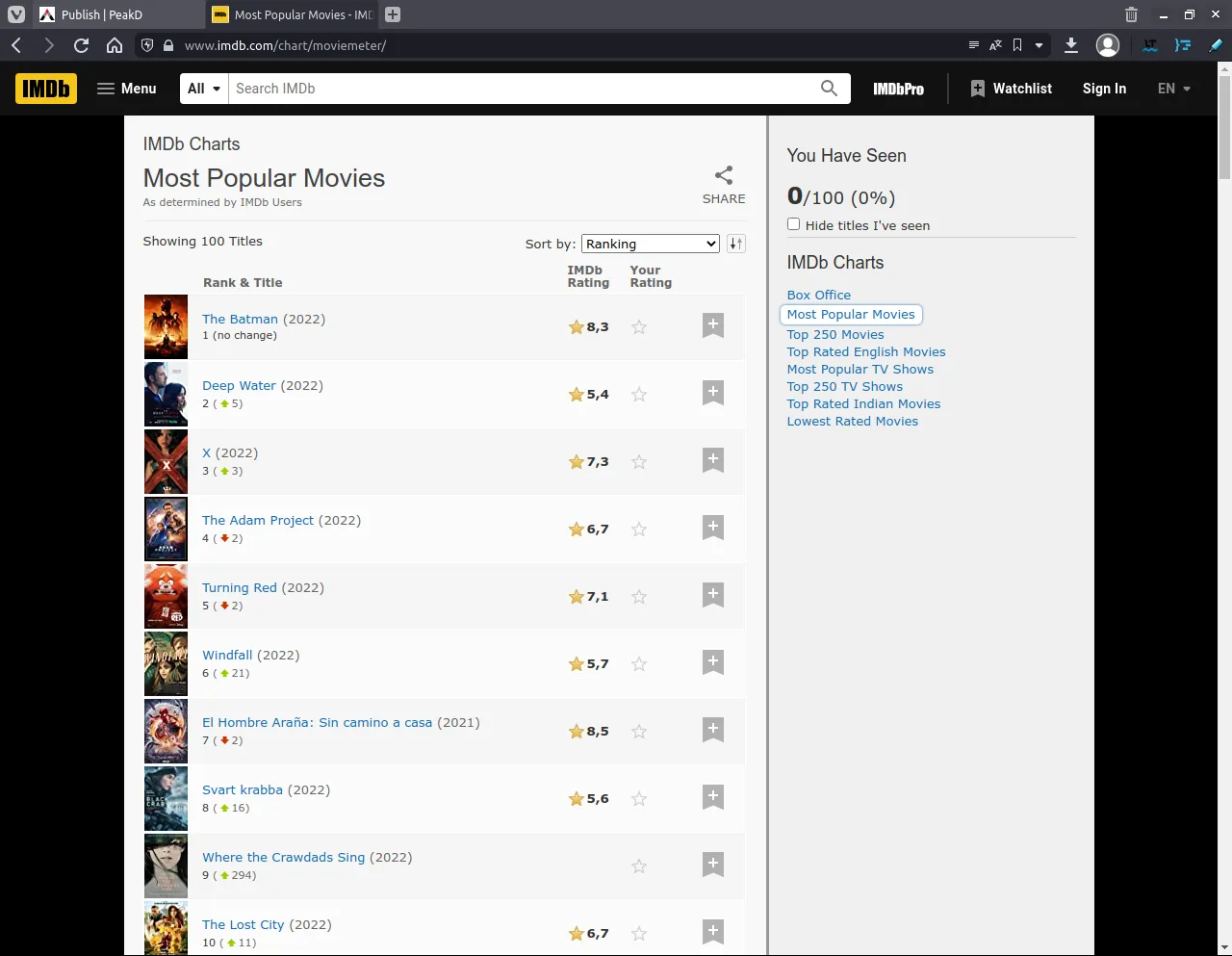
Hola Hivers. Buen día. He creado un nuevo script para usarlo en IMDB, IMDB es un sitio que almacena información sobre películas, es un sitio muy popular en él se puede consultar los estrenos más recientes así como también las películas más vistas o populares que realizan los usuarios en dicho sitio web. Para efectos prácticos, nuevamente utilicé las librerías httpx y selectolax, para obtener el título, año y calificación de varias películas en la sección de "Películas más populares".
Bueno, sin más preambulos les dejaré el script con sus respectivos resultados. Espero que lo disfruten, este no es más que otra publicación para mostrarle la utilidad y el alcance de estas librerías en otro de los muchos sitios alojados en el Internet.
Hello Hivers. Good morning. I have created a new script to use it in IMDB, IMDB is a site that stores information about movies, it is a very popular site where you can check the most recent releases as well as the most viewed or popular movies made by users on that website. For practical purposes, again I used the httpx and selectolax libraries, to obtain the title, year and rating of several movies in the "Most popular movies" section.
Well, without further ado, I'll leave you the script with its respective results. I hope you enjoy it, this is just another post to show you the usefulness and scope of these libraries in another of the many sites hosted on the Internet.
import httpx
from selectolax.parser import HTMLParser
page= 'https://www.imdb.com/chart/moviemeter/'
client = httpx.Client()
imdb = client.get(page)
parse= imdb.text
data_links = HTMLParser(parse)
search=data_links.css_first('tbody.lister-list')
title=search.css('td.titleColumn > a')
year=search.css('td.titleColumn > span')
rating=search.css('td.ratingColumn.imdbRating > strong')
for t,y,r in zip(title,year,rating):
dt=t.text(strip=True)
dy=y.text(strip=True)
dr=r.text(strip=True)
print({'title':dt,
'year':dy,
'rating':dr})