Cordiales Saludos
"La limpieza de datos (en inglés data cleansing o data scrubbing) es el acto de descubrimiento y corrección o eliminación de registros de datos erróneos de una tabla o base de datos. El proceso de limpieza de datos permite identificar datos incompletos, incorrectos, inexactos, no pertinentes, etc. y luego substituir, modificar o eliminar estos datos sucios ("data duty")." Fuente: wikipedia
En le entraga anterior eliminamos el índice que se genera automáticamente, hoy seguiremos con La limpieza de datos. Trataremos el tema: Nan = Not a Number. Los NaN los podemos ubicar visualmente y por medio de sentencias que nos dan una presición más exacta de su ubicación y cantidad, para luego determinar cuales podemos eliminar y cuales no.

Todos quisiéramos que los datos estén perfectos cuando llegan a nuestras manos para trabajarlos. Pero en realidad no es así. Cuando importamos los datos a nuestro Data Frame, si algunos valores no están definidos o no tienen ningún valor, la librería pandas automáticamente los completa con la palabra: NaN.
Para el ejercicio de hoy seguiremos con los datos de la Publicación anterior. Éste es el link del origen de los datos, los cuales los descargué en el entorno virtual donde estoy tranbajando.
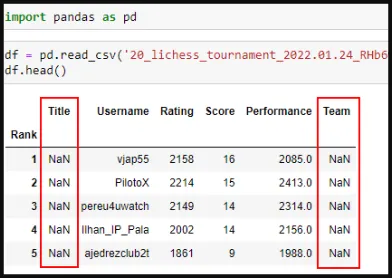
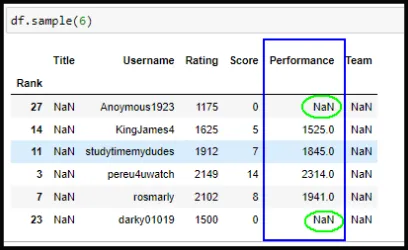
Al traer los datos a mi jupyter notebook, se ve claramente que la Columna Title y Team contienen el valor NaN.En este caso se ve a simple vista. Veamos el Capture de pantalla N01
Capture de pantalla N01
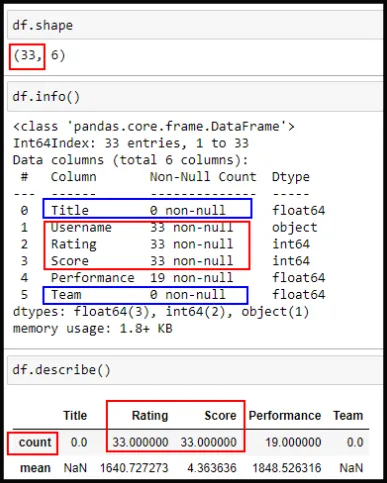
En casos donde sepamos que los datos son mayores (cientos o miles) no se ve a simple vista. Para determinar los valores NaN devemos recurrir a df.shape, df.info() y df.describe(). Con shape tenemos el número de filas (registros) y columnas. Marqué con un cuadro rojo el 33 (numero de registros) ya que info me arroja que las columnas Username, Rating y Score (recuadro rojo) están completas y se ve claramente en los recuadros azules (columnas Title y Team) que no hay ningún valor (pandas le agregó el Valor NaN). También es importante describe porque me cuanta los valores contenidos en Rating y Score. Se aprecia mejor en el Capture de pantalla N02
Capture de pantalla N02
Eliminando NaN de Columnas
Veremos dos formas para eliminar los NaN que tenemos en las columnas Title y Team, esto lo hacemos tomando en cuenta el estudio anterior.
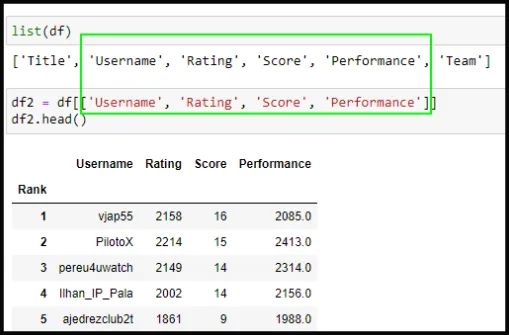
En la Capture de pantalla N03 al listar (con list) las columnas podemos seleccionar las columnas que nos interesa que aparezcan en el data Frame: Username, Rating, Score y Performance (recuadro verde) y omitir las que contienen los Nan, las cuales eliminaresmos.
Capture de pantalla N03
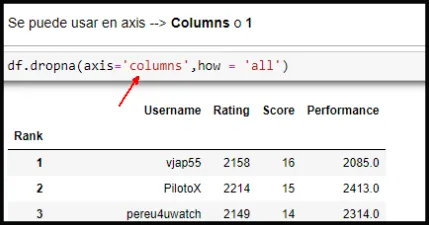
En la 2da forma de eliminación de columnas nos apoyaremos en la instrucción df.dropna() agregando dos argumentos. En la Capture de pantalla N04 ver línea roja (el 1 corresponde a las columnas) y la linea azul how = 'all' se usa para que elimine si todos los elementos (todos) son NaN. No eliminará la columna Performance porque contiene Valores y algunos NaN (Ver Capture de pantalla N05).
| Capture de pantalla N04 | Capture de pantalla N05 |
|---|---|
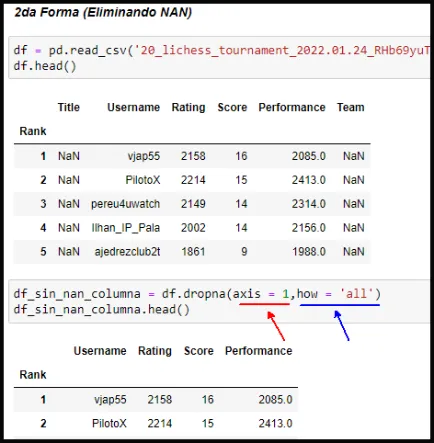 |  |
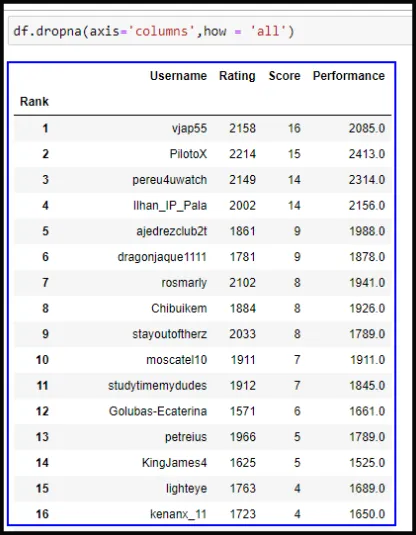
Veamos la Capture de pantalla N06. En los argumentos cambié el 1 por columns, funciona igual!
Capture de pantalla N06
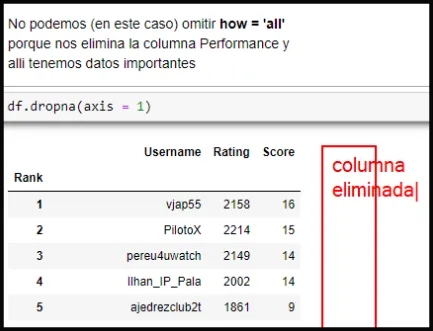
Debemos hacer buen uso de dropna, porque si omitimos how = 'all' nos eliminará toda columna que por lo menos contengo un NaN. veamos el Capture de pantalla N07
Capture de pantalla N07
Eliminando NaN de Filas
Para elimnar las filas NaN en este caso noté que quienes tienen NaN en Performance es porque no participaron en el torneo, a pesar de estar inscritos. En las captures de pantalla N08 y N09 vemos con los recuadros rojos los inscritos que no participaron.
| Capture de pantalla N08 | Capture de pantalla N09 |
|---|---|
 | 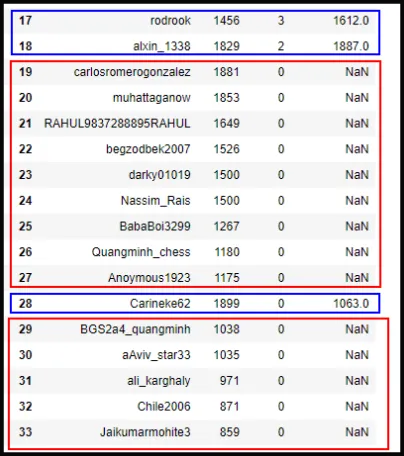 |
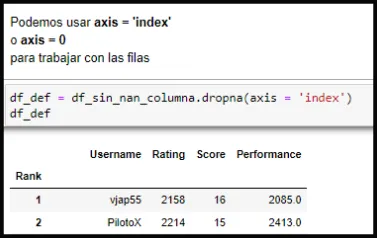
Con colocar solo el argumento axis = 0 se eliminaran todas las filas que contengan por lo menos un NaN. Veamos el Capture de pantalla N10
Es importante que coloquemos una nueva variable que contenga el df que ya se le ha realizado la limpieza de datos de las columna.
Si notamos el trabajo final se observa que todavía podemos seguir trabajando el df. Cambiar el 28 por 19 y podemos quitar el .0 de Performance (esto será tratado más adelante en otra publicación).
Capture de pantalla N10
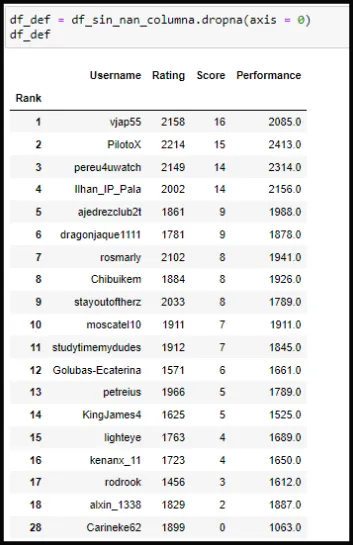
En el Capture de pantalla N11 podemos observar que podemos usar index para referirnos a los registros (filas).
Capture de pantalla N11
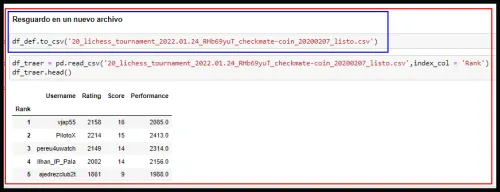
Para concluir debemos resguardar el Data Frame final en un nuevo archivo. El código usado, que ya lo conocemos esta en el Capture de pantalla N11
Capture de pantalla N11
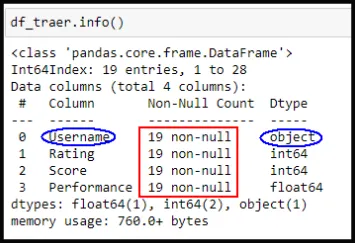
Veamos a continuación el Capture de pantalla N12, notaremos que aparecen todas las columnas con 19 valores. Esto nos permite verificar el trabajo realizado, el cual fue todo un éxito. Si existiera alguna falla volvemos a revisar para mejor la limpieza de datos.
Aquí salta a la vista lo marcado con azul, es otro tema que tocaremos más adelante. Cambiar a Username el tipo de variable object transformarlo en string.
En la próxima publicación seguiremos Trabajando el tema NaN para consolidar lo aprendido y agregar otras sentencias o comandos.
Ver el Cuaderno completo con los ejercicios de hoy en mi repositorio de Github
Capture de pantalla N12
Para quienes terminaron el Curso Gratis de Programación con python y para todos los interesados, ordené todas las publicaciones dedicadas a Data Science realizadas aquí en @hive, en una página web, para que tengan fácil acceso a cada entrada.
La dirección es Python Cumanés (Data Science) y aquí la dirección de pythoncumanes
Una vez más los invito a practicar, practicar, practicar... Hasta la próxima entrega, Feliz Día!

Todas las capturas de pantalla las realicé sobre el ejercicio que desarrollé para la siguiente publicación las cuales fueron editadas con el programa Inkscape
Entrega anterior
Limpiar, Organizar y Transformar los Datos
Invitación Especial
Apreciada comunidad extiendo mi invitación, para todos los que hacemos vida en esta maravillosa comunidad, a participar con la etiqueta #Hive para promocionar nuestras publicaciones en la red social: #Twitter. Para más detalles puedes consultar la publicación de @hive-data

Fuente:
Clases gratis de programación / Free programming classes
[ESP/ENG] Mi proyecto en Python/My project in Python.
I started a Ko-fi Page! Ko-fi helps creators get support from fans of their work. Please support or follow my page! If you like what I do and feel in tune with my work in creating content for free programming courses and chess publications without any profit interest. Give me a coffee... I will be very grateful!
Todos a programar!
Rafael Aquino