
Today is a special day for LLM enthusiasts, but not only for them, because by reading this post, you'll be able to fully set up your own Large Language Model without having to go through advanced tutorials or posses high-tech skills. My aim today is to provide enough guidance so that anyone can enjoy having their own private LLM, right at their fingertips

Now, you might be asking yourself: *Do I really need a private LLM?
And the answer is always YES! YES! YES!
First of all, there are no downsides, besides the resources your device uses, which is normal. You'll be using your device at full power and enjoying the full benefits:
- Your local LLM is your own, no data is leaked outside or used for training by other companies.
- You can ask any question without feeling censored,tracked or limited.
- You can use it without internet, offline.
- You can go camping and still use AI to learn something
- You can use it for coding guidance without fearing your code will be leaked
- You can have your own personal assistant
- Your own personal trainer, coach or chat companion
There are way more benefits than the ones I'm highlighting right now and you'll discover them for yourself!


This depends on your device configuration. The more powerful it is, the more parameters you will be able to run.
But first, I think you might be confused about my last sentence: 'the more parameters you will be able to run.' And you might ask yourself: 'What are those parameters?'
And i'll explain it in the simplest way: imagine parameters as the number of pages in a book. If a book has more pages, that means it contains more knowledge, right ? There parameters define how well-trained a LLM is, how many 'pages' it learned before becoming the final version you're going to use.
For our experiment, we'll use a Quantized LLM.
What is a Quantized LLM? Don't worry, I'll explain it in two different ways:
Tech-focused explanation: it converts floating-point numbers from 32-bit/16-bit to 8-bit integers (int8) or 4-bit (int4), improving speed, lowering power consumption, and reducing memory usage.
Simpler way: it's like turning big, heavy Lego blocks into smaller ones so your toy still works, but takes less space and is faster to build.
Now that we're on the same page and understand what a Quantized LLM is, we can answer the main question: 'What is the best LLM for me?'
If you have a decent GPU and RAM (>16 GB RAM recommended and ≥ 6 GB GPU), you can try models up to 8B parameters (8 billion parameters). If you're low on RAM and have an integrated GPU, I recommend trying 1.5B parameter models (1.5 billion parameters).
Perfect! Now let's learn about which models are trending right now and where the safest place to download them is. I'll also provide download links and explanations for the models I recommend.
The most popular LLMs are: Llama (released by Meta), DeepSeek R1 (released by DeepSeek), Qwen (released by Alibaba), Mistral (released by Mistral AI), Gemma 3 (released by Google), Phi-4 (released by Microsoft), and the recently released GPT-OSS (by OpenAI).
Now that we know the most popular LLMs, I'm going to recommend the only website you should download models from: Hugging Face → https://huggingface.co
For your safety, do not download LLMs from unknown sources, just stick to the official site, Hugging Face.

I'm trying to keep this post free of technical jargon or specialized knowledge that could overwhelm non-technical readers. However, there are a few terms you'll need to understand before we dive into downloading models. I'll explain them in two different ways, just like I did earlier.
Models don't come quantized by default,there are special teams, driven by kindness and love for the community, that do all the work for you. While every single free contribution is deeply appreciated and loved by the community, some models are better than others because of the quantization process and how each team chooses to operate.
From my personal point of view, the best teams are Unsloth AI, lmstudio-community, and TheBloke. That said, they don't host every model you might be looking for, so you can (and should) experiment with other authors to find what works best for you. In this guide, we will also include some authors who aren't as well known.
When you search for a specific model, you'll be looking for a file format such as GGUF.
This is important, let me explain what GGUF stands for and who's the genius behind it:
Tech-focused explanation: a file format optimized for very fast loading and efficient inference. It was developed by Georgi Gerganov (ggerganov), the creator of the llama.cpp framework.
Simple explanation: it's like putting your favorite toy in a special box that makes it super fast to take out and play with anytime you want.
Perfect! Now that we know what to look for and which teams to choose from, let's check out a few models i recommend. :smile:
Attention: You can skip downloading the model manually if you're going to install LM Studio ( check next step ), just remember the name of the model you want to try
For coding purposes:
- Deepseek-coder (https://huggingface.co/TheBloke/deepseek-coder-6.7B-base-GGUF )
- Qwen2.5-coder (https://huggingface.co/unsloth/Qwen2.5-Coder-7B-Instruct-128K-GGUF )
- Qwen3-Coder (https://huggingface.co/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF )
- Llama-2-coder (https://huggingface.co/TheBloke/Llama-2-Coder-7B-GGUF )
- Qwen2-5-coder (https://huggingface.co/lmstudio-community/Qwen2.5-Coder-3B-GGUF ) -> this one works with code autocomplete, for programmers
For general purposes:
- Gemma (https://huggingface.co/unsloth/gemma-3n-E4B-it-GGUF )
- Qwen3-4B (https://huggingface.co/unsloth/Qwen3-4B-Thinking-2507-GGUF )
- Phi-4-mini (https://huggingface.co/unsloth/Phi-4-mini-instruct-GGUF )
For general purposes + vision capability
- Llama-3.1 (https://huggingface.co/FiditeNemini/Llama-3.1-Unhinged-Vision-8B-GGUF )
For chats/therapy/roleplay:
- Llama-3 (https://huggingface.co/mradermacher/Llama-3-8B-Therapy-Model-GGUF )
- Lexi-Llama (https://huggingface.co/bartowski/Lexi-Llama-3-8B-Uncensored-GGUF )
If your system is very low-end
- TinyLlama-1.1B-Chat (https://huggingface.co/TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF )
What files to download ? I recommend downloading only Q4_K_M as this version offers a good balance between speed and quality
Please use these models responsibly


The software I recommend for both tech users and casual users is LM Studio , it's extremely easy to use, and you can also download models directly from within the software ( it pulls models from Hugging Face, so you don't have to worry about untrusted sources).And of course, it's FREE for both personal and work use.
You can download it from their official website ( please don't download it from random sources ): https://lmstudio.ai/
Install LM Studio in a partition with enough free space (100Gb+ if you want to test multiple models):
Once you installed it, run the software and you should see this interface:
On the left side, you will see a "magnifying glass" icon labeled "Discover", Click on it
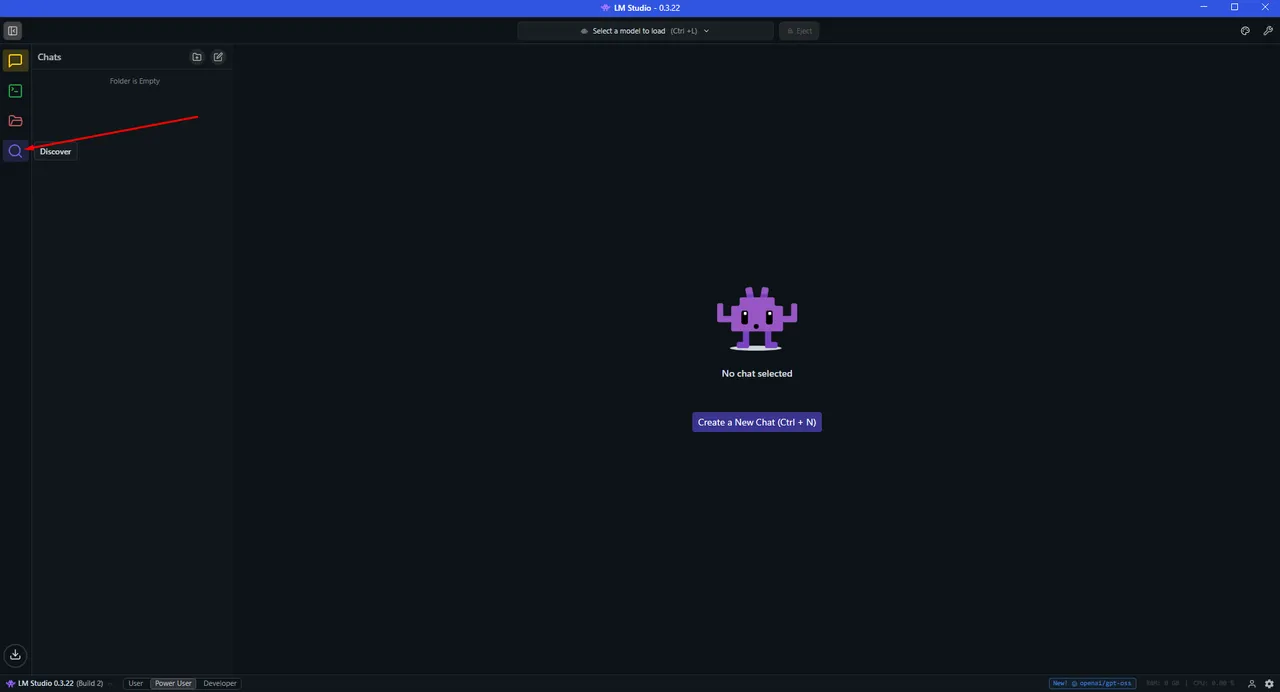
It's very important to select GGUF format

Then, search for a model you're interested in from the list i showed you earlier, for example, i want a general-use model, Google Gemma
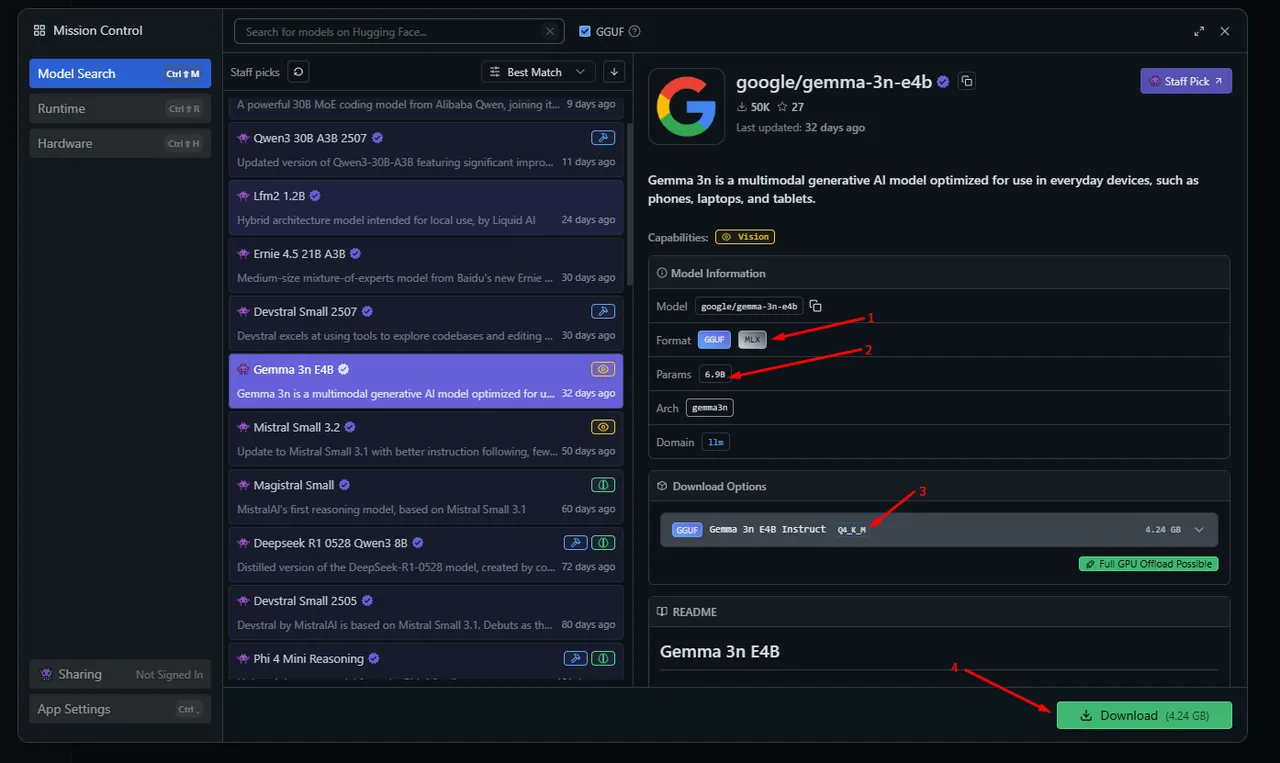
There are four important things to check when downloading a model:
- Format: Make sure it's GGUF or MLX(modern mac only)
- Parameters: Make sure your device can handle the specified parameters. (if you're not sure, just download and try loading the model,this way you can downgrade or upgrade the parameters as needed)
- Version: Always make sure it's Q4_K_M as it's the most recommended and balanced
- Download: After you verified everything, click on Download Button
After you click download, a new Download tab will open where you can see the progress.
Once the model has been downloaded successfully to your device, you will receive a similar notification:
Now, click on the top bar where it says 'Load a model'
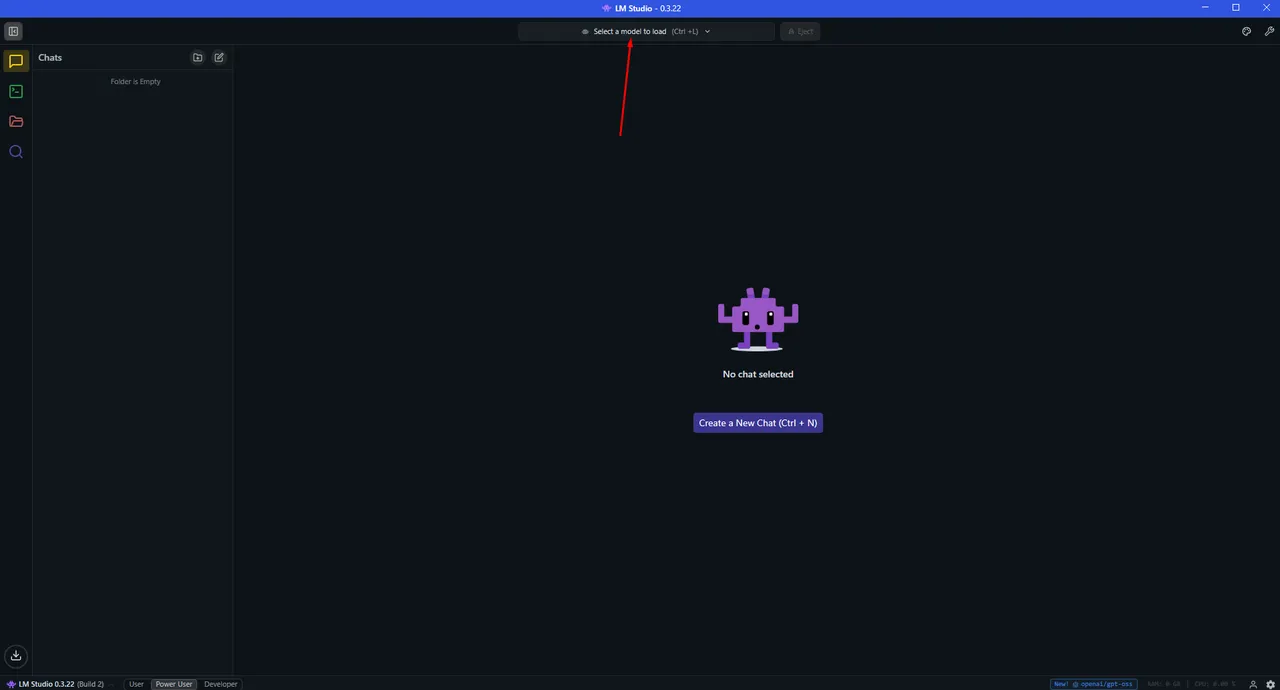
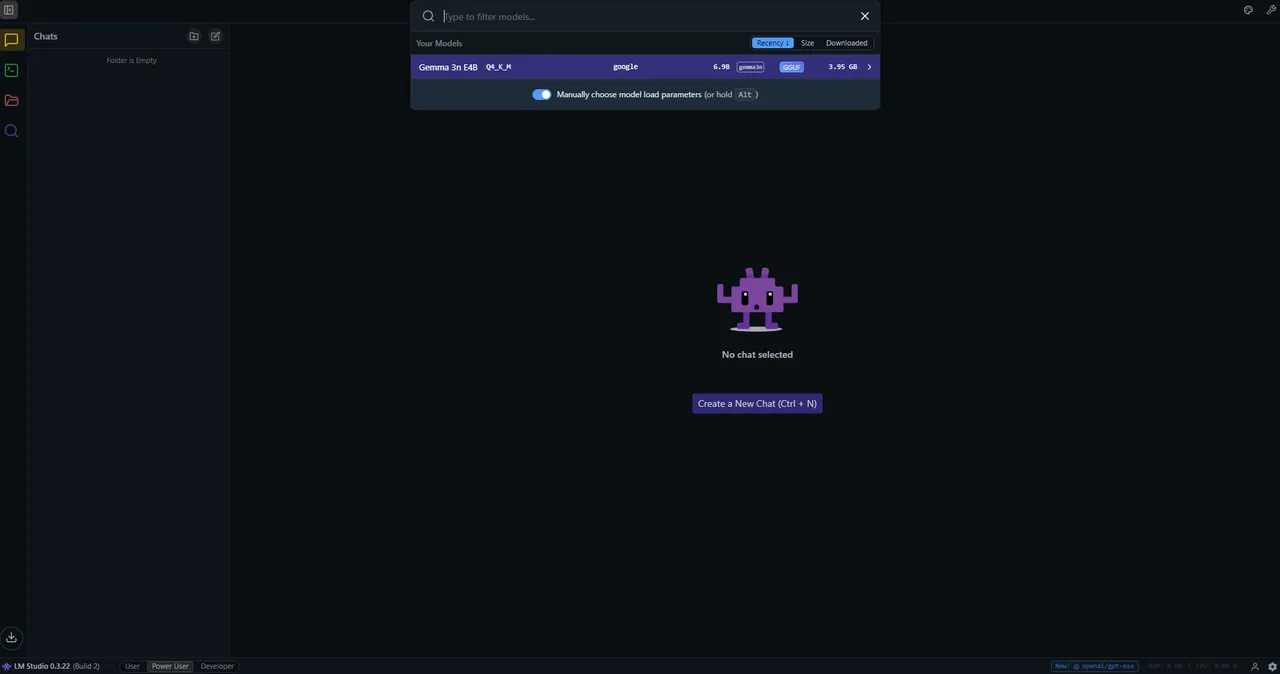
And select the model you just downloaded
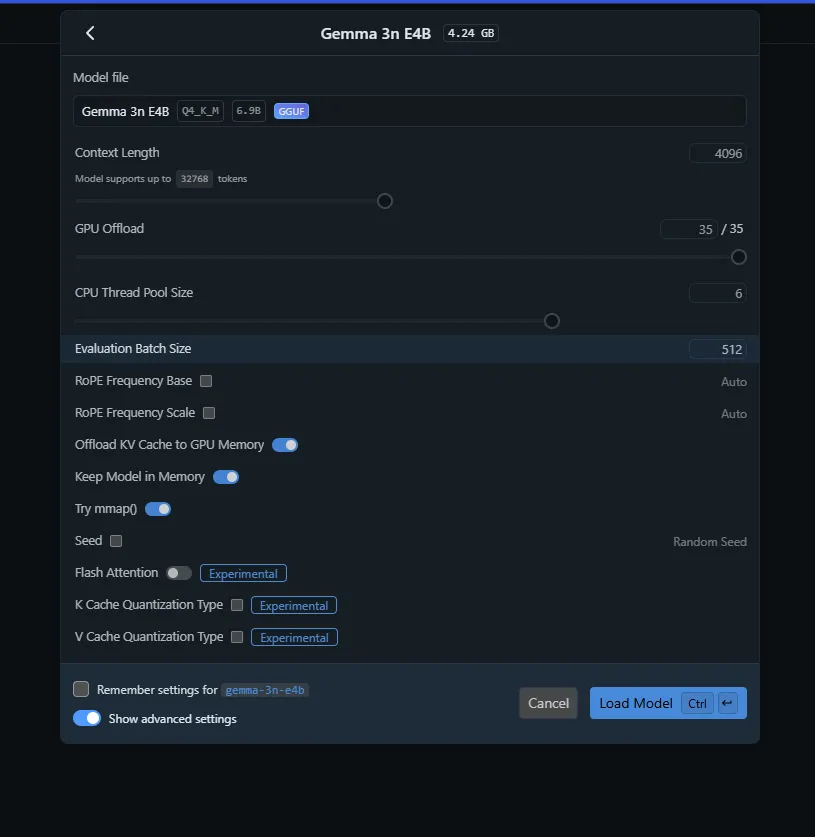
This part is more advanced, but you can keep everything at its default settings. The only thing you might want to adjust is GPU offload, if you have a good GPU, try to offload as much as possible onto it. Also, close any background programs that might use the GPU (Youtube videos,games,etc) to free up VRAM. Then click 'Load Model'
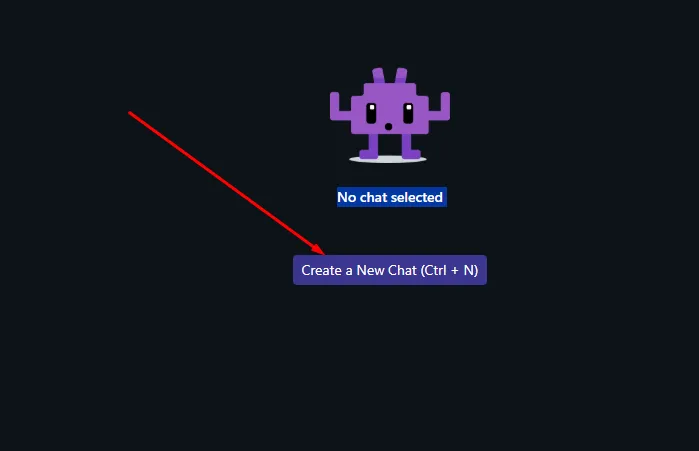
After the model has been loaded, click on New Chat
And now you can chat with your own LOCAL and PRIVATE LLM :smile:
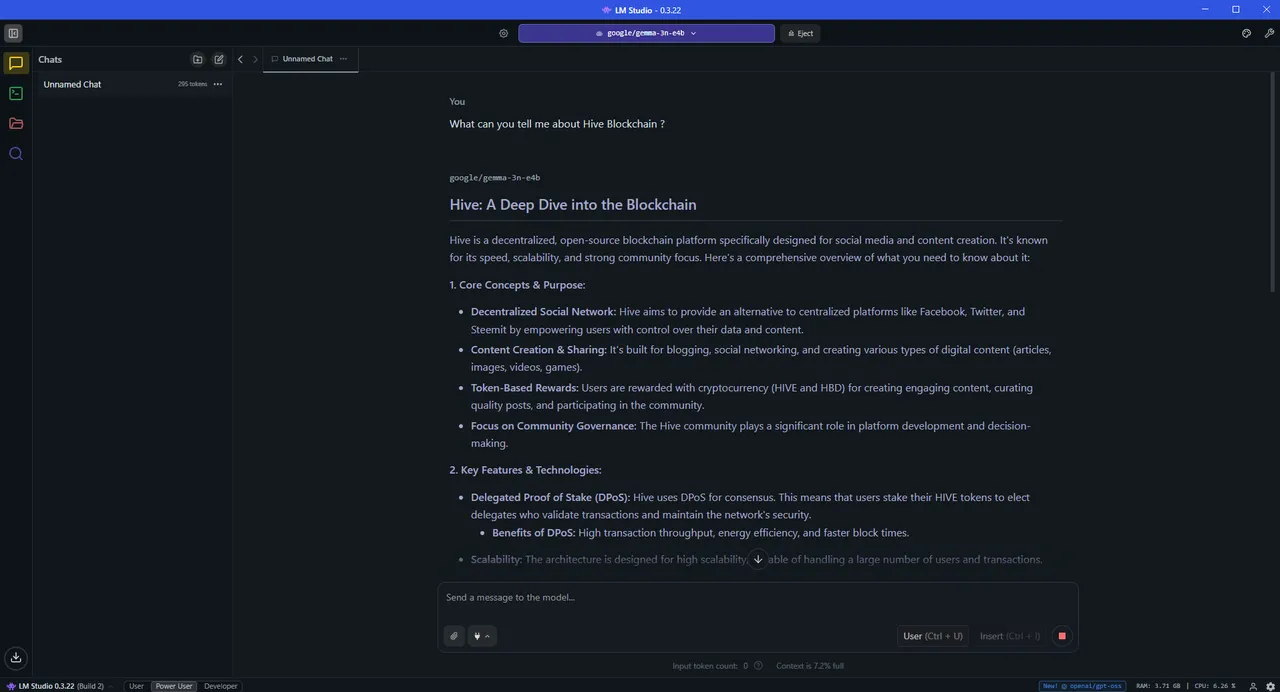
And that's it ! You are now running your own private AI, completely under your control. No subscriptions, no data leaks , no restrictions, no censorship and ready whenever you are!
If you'd like to see more tutorials from me, don't hesitate to leave a reply, i'm thinking about creating new guides on connecting local AI to games and websites, building your own fully voice-enabled assistant, and integrating MCP tools.
But until next time, bye for now !

Sources:
- Gifs: tenor