Hey everyone,
It seems like the Market Viewr app has been getting a bit of attention this week, not because I'm trying to dwell on it, but because new challenges and improvements keep popping up! This latest update addresses an interesting issue I encountered with tokens that have very large numbers of holders.
The Problem: Hive-Engine's 10,000 Record Speedbump
I noticed that for tokens with extremely long richlists – think of popular ones like ARCHON or PIZZA, which can have well over 10,000 individual holders (PIZZA has around 18,948!) – Market Viewr was either failing to load the complete richlist or would sometimes just hang.
After digging into it, I learned something new (or perhaps, re-learned something I'd forgotten): the Hive-Engine API has a hard pagination limit. You can't retrieve more than 10,000 records for a single query, period. So, if a token has more holders than that, the standard way of paginating through the balances (offset by 1000, get next 1000, etc.) hits a wall.
The Workaround: Iterating by Prefix
To get around this and attempt to build a more complete richlist for these massive tokens, I've implemented a new approach in Market Viewr. Instead of just trying to paginate through the entire balance list in one go, the tool now iterates through all possible starting characters for account names (a-z, 0-9, and even '_').
For each prefix (like "a", "b", "c", etc.), it fetches all account balances starting with that letter, paginating in chunks of 1000 until all accounts for that prefix are retrieved. It then combines these, removes duplicates (using a seen_accounts set just in case), separates out the 'null' account balance for burned token calculation, and finally sorts the compiled list by balance.
You can see the gist of the change in the get_richlist function from the git diff I was working on:
# Simplified concept from the diff:
# ...
prefixes = list(string.ascii_lowercase) + list(string.digits) + ["_"]
seen_accounts = set()
for prefix in prefixes:
offset = 0
while True:
batch = he_api.find(
# ... query with account starting with prefix ...
)
if not batch:
break
for holder in batch:
# ... process holder, add to richlist if not 'null' and not seen ...
# ...
offset += page_size
# ...
richlist.sort(key=get_balance, reverse=True)
# ...
The Trade-off and a Question for You
This new method does allow Market Viewr to build a much more complete richlist for tokens that exceed the 10k holder limit. However, as you can imagine, making dozens of separate queries to the Hive-Engine API (one set for 'a' accounts, one for 'b' accounts, etc.) can take a significantly longer time to load for these very large tokens.
So, this brings me to a question for you all, the users:
For tokens with extremely long richlists (10,000+ holders):
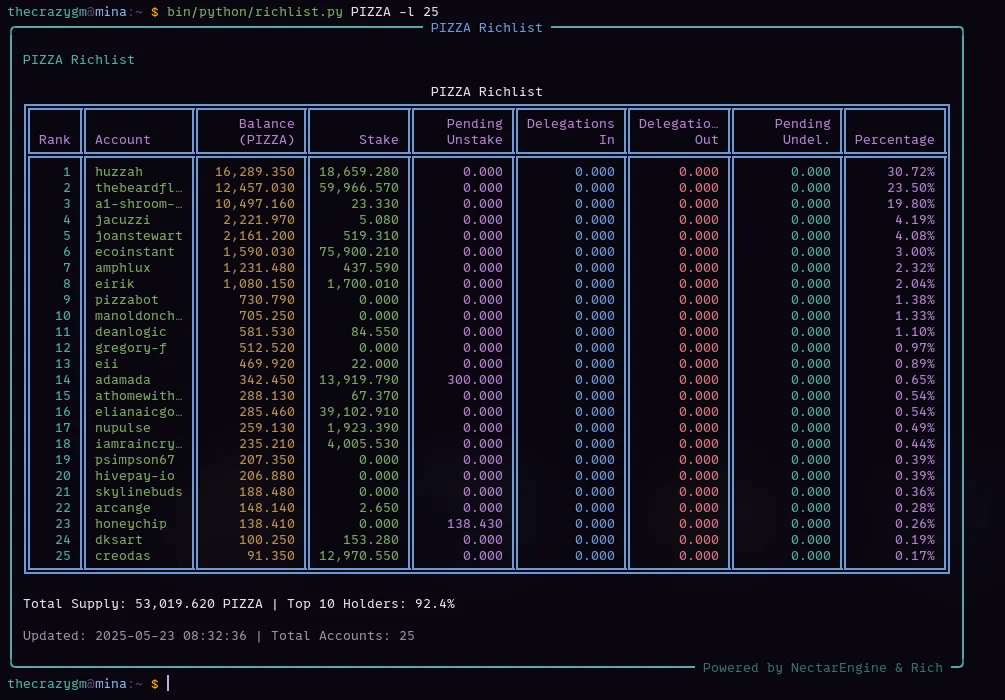
- Do you prefer the application to attempt to load the entire richlist, even if it means a noticeably longer loading time for those specific tokens?
- Or, would you prefer it if Market Viewr capped the richlist display at a certain number (say, the top 5,000 or 10,000 holders) to ensure faster load times, even if it means not seeing every single tiny holder for the biggest tokens?
I'm trying to balance completeness with performance and usability. Your thoughts on this would be really helpful as I continue to refine the tool! Let me know in the comments what your preference would be.
As always,
Michael Garcia a.k.a. TheCrazyGM