TensorFlow 머신 러닝 코드는 실행에 앞서 Computational Graph 즉 그래프를 생성하게 되어 있다. Session 단계에서는 생성된 그래프를 이용하여 입력되는 데이터에 대해 언제라도 동일한 그래프를 사용하여 연산을 실행한다.
numPy 스타일 뉴럴네트워크 코드나 PyTorch 코드와 비교할 목적으로 GPU 연산에 따른 소요 시간을 그래프 셍성 시간과 Session 실행 시간으로 나누어 조사해 보자.
헤더 영역에서 tensorflow, numpy 및 time을 부르고 시작 시간을 기록한다.
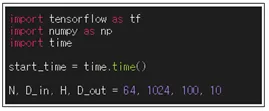
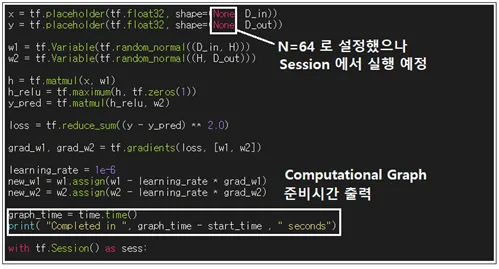
머신 러닝 학습을 위한 입력 데이터는 항상 placeholder를 사용하여 설정한다. 실제 메모리에서 차지하게 될 크기는 Session에서 구체적으로 설정이 된다. Graph 설정 시점까지의 소dy 시간을 조사해 보자. TensorFlow에서 Graph 설정은 한 번이루어지며 Session에서 이 Graph를 이용한 연산이 무수히 반복될 수 있다.
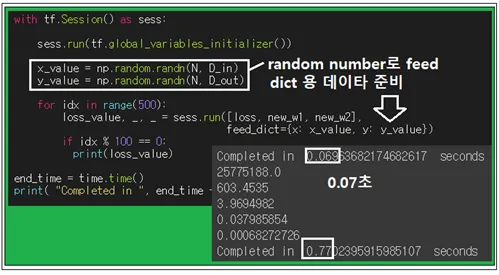
Session에서 실제 연산을 위한 데이터 x 와 y를 numpy 의 정규분포 random number 명령으로 생성하여 feed dict에 넣어준다. Colabo GPU 연산 결과 Graph 연산에 0.07초 걸렸고 학습에 0.77초 소요되었다.
NumPy 코드 1.27초, PyTorch 0.6초, TensorFlow 0.84초로서 PyTorch 연산 방식이 GPU 연산에 유리함을 알 수 있다. 매트릭스 사이즈를 충분히 크게 잡으면 상호 연산 속도 비교가 극명하게 이루어질 수 있다. 하지만 지금의 예제만 하더라도 연산 속도를 비교하는데 충분하리라 보인다.
#tensorflow_nn
import tensorflow as tf
import numpy as np
import time
start_time = time.time()
N, D_in, H, D_out = 64, 1024, 100, 10
x = tf.placeholder(tf.float32, shape=(None, D_in))
y = tf.placeholder(tf.float32, shape=(None, D_out))
w1 = tf.Variable(tf.random_normal((D_in, H)))
w2 = tf.Variable(tf.random_normal((H, D_out)))
h = tf.matmul(x, w1)
h_relu = tf.maximum(h, tf.zeros(1))
y_pred = tf.matmul(h_relu, w2)
loss = tf.reduce_sum((y - y_pred) ** 2.0)
grad_w1, grad_w2 = tf.gradients(loss, [w1, w2])
learning_rate = 1e-6
new_w1 = w1.assign(w1 - learning_rate * grad_w1)
new_w2 = w2.assign(w2 - learning_rate * grad_w2)
graph_time = time.time()
print( "Completed in ", graph_time - start_time , " seconds")
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
x_value = np.random.randn(N, D_in)
y_value = np.random.randn(N, D_out)
for idx in range(500):
loss_value, _, _ = sess.run([loss, new_w1, new_w2],
feed_dict={x: x_value, y: y_value})
if idx % 100 == 0:
print(loss_value)
end_time = time.time()
print( "Completed in ", end_time - graph_time , " seconds")