머신 러닝 책의 대부분에서 다루고 있는 손글씨 관련 데모 입니다. 사람의 손으로 쓴 숫자를 학습을 통해 맞추도록 하는 데모입니다. 매우 유명한 데모인데 Azure ML에서도 동일하게 사용할 수 있습니다. ^^
파이썬 수업에서 많이 다루는 os모듈과 gzip모듈이 나오네요. 생각보다 코드가 상당한 단순합니다.
import os
import urllib.request
os.makedirs('./data', exist_ok = True)
urllib.request.urlretrieve('http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz',
filename='./data/train-images.gz')
urllib.request.urlretrieve('http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz',
filename='./data/train-labels.gz')
urllib.request.urlretrieve('http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz',
filename='./data/test-images.gz')
urllib.request.urlretrieve('http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz',
filename='./data/test-labels.gz')
print('Code executed')
import gzip
import numpy as np
import struct
def load_data(filename, label=False):
with gzip.open(filename) as gz:
struct.unpack('I', gz.read(4))
n_items = struct.unpack('>I', gz.read(4))
if not label:
n_rows = struct.unpack('>I', gz.read(4))[0]
n_cols = struct.unpack('>I', gz.read(4))[0]
res = np.frombuffer(gz.read(n_items[0] * n_rows * n_cols),
dtype=np.uint8)
res = res.reshape(n_items[0], n_rows * n_cols)
else:
res = np.frombuffer(gz.read(n_items[0]), dtype=np.uint8)
res = res.reshape(n_items[0], 1)
return res
def one_hot_encode(array, num_of_classes):
return np.eye(num_of_classes)[array.reshape(-1)]
#load data
X_train = load_data('./data/train-images.gz', False) / 255.0
y_train = load_data('./data/train-labels.gz', True).reshape(-1)
X_test = load_data('./data/test-images.gz', False) / 255.0
y_test = load_data('./data/test-labels.gz', True).reshape(-1)
print('Code executed')
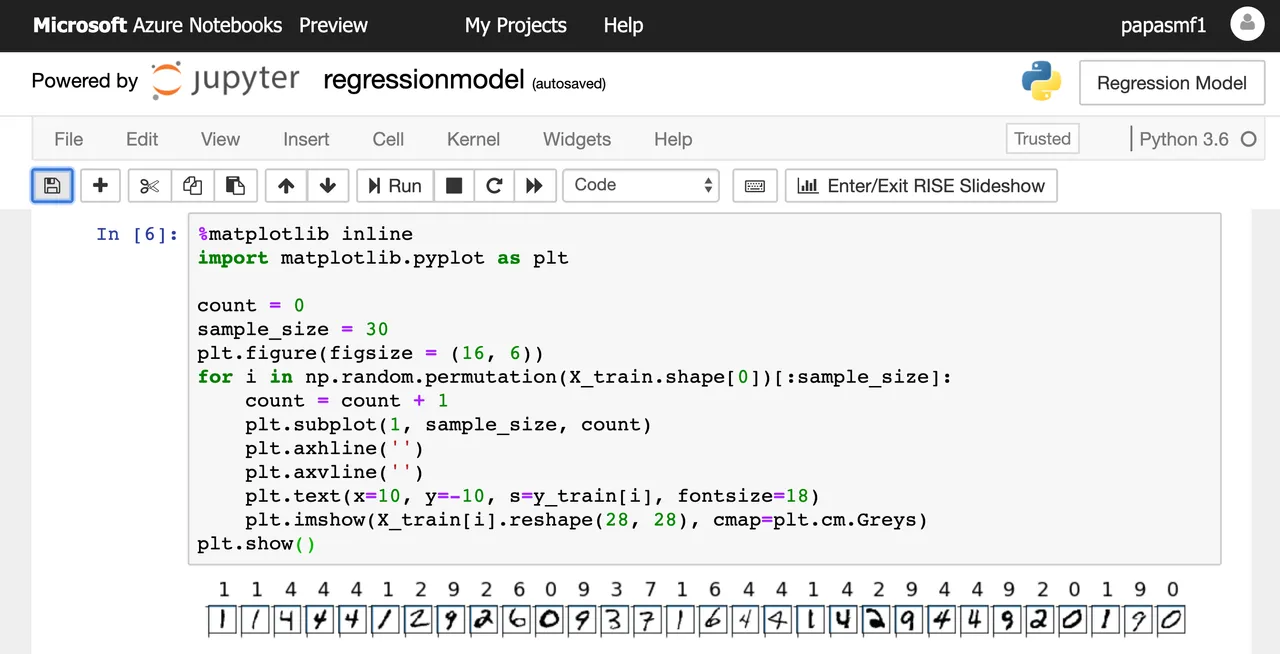
%matplotlib inline
import matplotlib.pyplot as plt
count = 0
sample_size = 30
plt.figure(figsize = (16, 6))
for i in np.random.permutation(X_train.shape[0])[:sample_size]:
count = count + 1
plt.subplot(1, sample_size, count)
plt.axhline('')
plt.axvline('')
plt.text(x=10, y=-10, s=y_train[i], fontsize=18)
plt.imshow(X_train[i].reshape(28, 28), cmap=plt.cm.Greys)
plt.show()
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(X_train, y_train)
y_hat = clf.predict(X_test)
print(np.average(y_hat == y_test))
print('Code executed')
0.9201
Code executed
ws = Workspace.get(name='myworkspace',
subscription_id='63772560-ab7e-488c-82ea-458d8b779f6f',
resource_group='myresourcegroup')
ws.get_details()
from azureml.core import Workspace, Experiment
experiment = Experiment(workspace = ws, name = 'my-first-experiment')
run = experiment.start_logging()
run.log('trial', 1)
run.complete()
print('Code executed')
ws.get_details()
print(run.get_portal_url())
from azureml.core.compute import AmlCompute
from azureml.core.compute import ComputeTarget
import os
compute_name = os.environ.get("AML_COMPUTE_CLUSTER_NAME", "cpucluster")
min_nodes = os.environ.get("AML_COMPUTE_CLUSTER_MIN_NODES", 0)
max_nodes = os.environ.get("AML_COMPUTE_CLUSTER_MAX_NODES", 3)
vm_size = os.environ.get("AML_COMPUTE_CLUSTER_SKU", "STANDARD_D2_V2")
provisioning_config = AmlCompute.provisioning_configuration(vm_size = vm_size,
min_nodes = min_nodes,
max_nodes = max_nodes)
compute_target = ComputeTarget.create(ws, compute_name, provisioning_config)
print('Code executed')
ds = ws.get_default_datastore()
ds.upload(src_dir='./data', target_path='mnist', overwrite=True,
show_progress=True)
print('Code executed')
import os
folder_training_script = './trial_model_mnist'
os.makedirs(folder_training_script, exist_ok=True)
%%writefile $folder_training_script/train.py
import gzip
import numpy as np
import struct
def load_data(filename, label=False):
with gzip.open(filename) as gz:
struct.unpack('I', gz.read(4))
n_items = struct.unpack('>I', gz.read(4))
if not label:
n_rows = struct.unpack('>I', gz.read(4))[0]
n_cols = struct.unpack('>I', gz.read(4))[0]
res = np.frombuffer(gz.read(n_items[0] * n_rows * n_cols),
dtype=np.uint8)
res = res.reshape(n_items[0], n_rows * n_cols)
else:
res = np.frombuffer(gz.read(n_items[0]), dtype=np.uint8)
res = res.reshape(n_items[0], 1)
return res
def one_hot_encode(array, num_of_classes):
return np.eye(num_of_classes)[array.reshape(-1)]
import argparse
import os
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.externals import joblib
from azureml.core import Run
parser = argparse.ArgumentParser()
parser.add_argument('--data-folder', type=str, dest='data_folder',
help='data folder mounting point')
parser.add_argument('--regularization', type=float, dest='reg',
default=0.01, help='regularization rate')
args = parser.parse_args()
data_folder = os.path.join(args.data_folder, 'mnist')
print('Data folder:', data_folder)
X_train = load_data(os.path.join(data_folder, 'train-images.gz'), False) / 255.0
X_test = load_data(os.path.join(data_folder, 'test-images.gz'), False) / 255.0
y_train = load_data(os.path.join(data_folder, 'train-labels.gz'), True).reshape(-1)
y_test = load_data(os.path.join(data_folder, 'test-labels.gz'), True).reshape(-1)
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape, sep='\n')
run = Run.get_context()
print('Train a logistic regression model with regularization rate of', args.reg)
clf = LogisticRegression(C=1.0/args.reg, random_state=42)
clf.fit(X_train, y_train)
print('Predict the test set')
y_hat = clf.predict(X_test)
acc = np.average(y_hat == y_test)
print('Accuracy is', acc)
run.log('regularization rate', np.float(args.reg))
run.log('accuracy', np.float(acc))
os.makedirs('outputs', exist_ok=True)
joblib.dump(value=clf, filename='outputs/sklearn_mnist_model.pkl')
print('Code executed')
from azureml.train.estimator import Estimator
script_params = {
'--data-folder': ds.as_mount(),
'--regularization': 0.8
}
est = Estimator(source_directory=folder_training_script,
script_params=script_params,
compute_target=compute_target,
entry_script='train.py',
conda_packages=['scikit-learn'])
run = experiment.submit(config=est)
run
print('Code executed')

처음에는 모든 것이 어렵게 느껴졌는데 이제는 여러번 반복하면서 파이썬, 데이터 사이언스, Azure 클라우드가 하나로 합쳐지니 너무 재미있습니다. 오랜동안 공부하고 준비해야 하는 주제이지만 엉덩이 무겁게 시간을 투자하면 반드시 성공할 수 있는 스킬 중에 하나라고 생각합니다. ^^ 한번 도전해 보세요.