
Wstęp
Chciałem napisać artykuł o konkretnej implementacji CI. Zacząłem pisać wstęp i tak wyszedł właściwie osobny post.
Chyba każdy, kto już chwilę programuje konfigurował środowisko tak, aby automatyzować pewne procesy. Na początku kariery, nie jest to jednak proste. Pamiętam, że była to dla mnie czarna magia. Sam efekt nie był skomplikowany, bo widziałem, że testy przeszły, lub nie. Ale jak to się działo w środku? Co odpalało te testy, gdzie się to odpalało? Skąd github o tym wiedział. Tego nie rozumiałem.
Co to jest Continuous Integration?
Aby nie wchodzić w definicje, w skrócie można powiedzieć, że jest to automatyzowanie pewnych powtarzalnych czynności, które występują w projekcie. Sprowadza się to do tego, że kiedy dostarczamy jakąś funkcjonalność, automatycznie wykonywane jest sprawdzenie kodu (składnia, testy, błędy itp). Często automatyzuje się również deploy na serwery testowe, oraz wspomaga deploy na produkcje. (Przez wspomaganie rozumiem, sprowadzenie deploy-u produkcyjnego do kliknięcia w jeden przycisk)
Jak to działa?
Aby mówić o CI, musimy mieć jakiś serwer, na którym będzie stało odpowiednie oprogramowanie (np Jenkins). Często nazywa się to po prostu “serwerem CI”. Powinna to być oddzielna maszyna, ponieważ proces buildu pochłania zwykle sporo zasobów.
W oprogramowaniu tym, wykonywane są po kolei komendy związane z instalacją i uruchomieniem testów na aplikacji. Generalnie są to te same komendy, które pozwalają nam odpalić testy aplikacji w środowisku lokalnym. Serwer CI współpracuje z odpowiednim pluginem w repozytorium. Zarówno github, bitbucket, czy gitlab, mają takie pluginy.
W github-ie wygląda to tak:
Plugin w repozytorium służy do wyświetlania tego co zrobił CI, oraz do komunikowania się z nim. Trzeba więc zainstalować i skonfigurować plugin w repozytorium, oraz aplikacje CI na serwerze.
Najczęściej konfiguracja sprowadza się to do określenia, kiedy ma się wykonać jakiś proces/build w CI. Oczywiście dla jednego projektu może być kilka różnych procesów / buildów. Ja zwykle robię dwa:
- odpalenie buildów przy każdym stworzonym pull-requeście
- odpalenie deploy-u na serwer testowy przy każdym zmergowaniu feature-a do gałęzi dev

Przykładowy widok buildów dla poszczególnych gałęzi w bitbucket.com
Jak dokładnie wyglądają polecenia buildu?
zainstaluj aplikacje czyli zbiór poleceń w typu apt-get install nodejs
bundle exec rspec - odpalenie testów
bundle exec rubocop sprawdzenie składni i formatowania kodu
bundle exec reek sprawdzenie jakości kodu
Powyższe komendy są używane do aplikacji napisanej w Ruby.
W zależności od tego, w jakim języku i frameworku napisany jest nasz projekt, polecenia oczywiście będą inne. Ilość poleceń zależy od tego jak dużo narzędzi wykorzystujemy.
Dostępne CI
Na rynku dostępnych jest bardzo dużo różnych CI. Zwykle mają plik konfiguracyjny wg. którego wykonywane są polecenia. Opiszę tylko te narzędzia, które samodzielnie konfigurowałem.
Jenkins
Działa w taki sposób, że instalujemy na własnym serwerze aplikacje Jenkins. Następnie w interface graficznym konfigurujemy projekt. Określamy kiedy build ma się wykonać, podajemy adres repozytorium, klucze autentykacyjne itp. Na koniec w okienku wpisujemy komendy bash-owe które wykonają build. Jenkins ma stosunkowo wysoki próg wejścia. Jak dla mnie jest trochę reliktem przeszłości. Dziś są dostępne dużo łatwiejsze rozwiązania.
Travis
Aby korzystać z Travisa trzeba dodać w repozytorium (testowalem tylko z github) w katalogu głównym plik .travis.yml. W tym pliku wykonujemy komendy jakie mają się wykonać.
Używam travisa kiedy tworzę biblioteki do ruby, ponieważ podczas tworzenia takiej biblioteki automatycznie generuje się plik konfiguracyjny do niego. Dla Open-sourcowych projektów jego używanie jest darmowe. Dodatkowo w pliku readme możemy dodać sexi button(build passing).
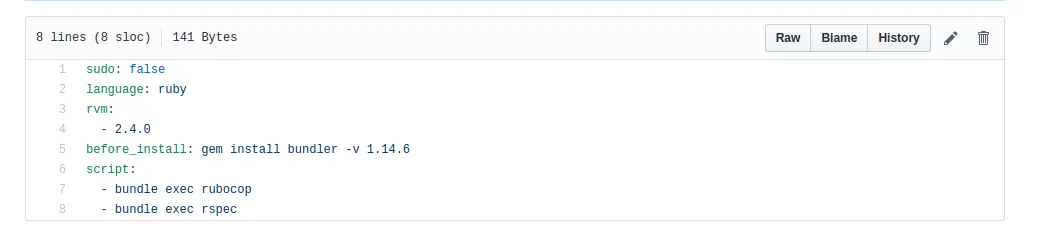
Przykładowy plik konfiguracyjny dla Travis:
GitLab CI
Aby korzystać z CI gitlaba, trzeba mieć własnego hostowanego gitlab-a na jednym serwerze, oraz zainstalować na drugim aplikacje do CI. Instalacja jest łatwa, ale trzeba mieć dwa osobne serwery. Później podobnie jak w przypadku Travis-a mamy plik konfiguracyjny, który dodajemy do głównego katalogu aplikacji. Jego nazwa to .gitlab-ci.yml.
Reszta dzieje się już automagicznie, w zależności od tego co mamy w pliku konfiguracyjnym.
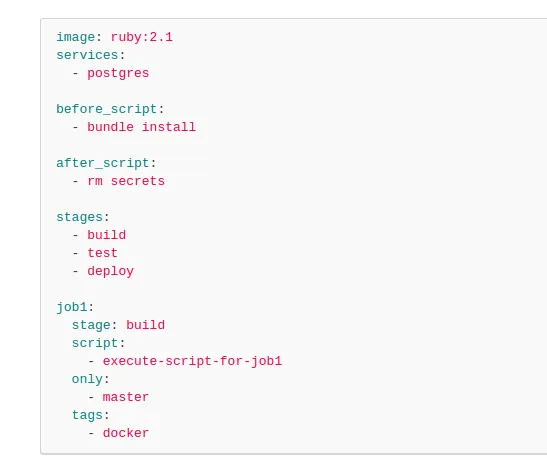
Trzeba wspomnieć, że ma on naprawdę duże możliwości. Poniżej wklejam screen z dokumentacji gitlab . Znajduje się on na stronie: GitLab Documentation. GitLab CI jest oparty na Dockerze.
Bitbucket Pipelines
I wreszcie CI któremu chciałem poświęcić ten post, jednak ze względu na przydługawy wstęp napiszę o nim w następnej części. Teraz wspomnę tylko, że dla małych projektów jest darmowy i nic nie trzeba instalować.
Zdjęcie tytułowe pochodzi z https://www.pexels.com