오늘 작성할 내용은 지금까지의 내용을 전부 포함해서 정리한 내용을 다루고자 한다.
지금까지 다룬 내용들은 폐암이라는 특정 질병에 대해 다루면서 얘기를 하지만, 좀더 넓은 범위에서 다시 정리해서 얘기 해보고자 한다.
내가 지금 하고자 하는 CAD system 의 전체적인 단계와 그 단계별로 현재까지 나온 방법들에 대해 정리해보고자 한다.
CAD system 의 가장 큰 process 를 다시 보여주면 아래와 같다.
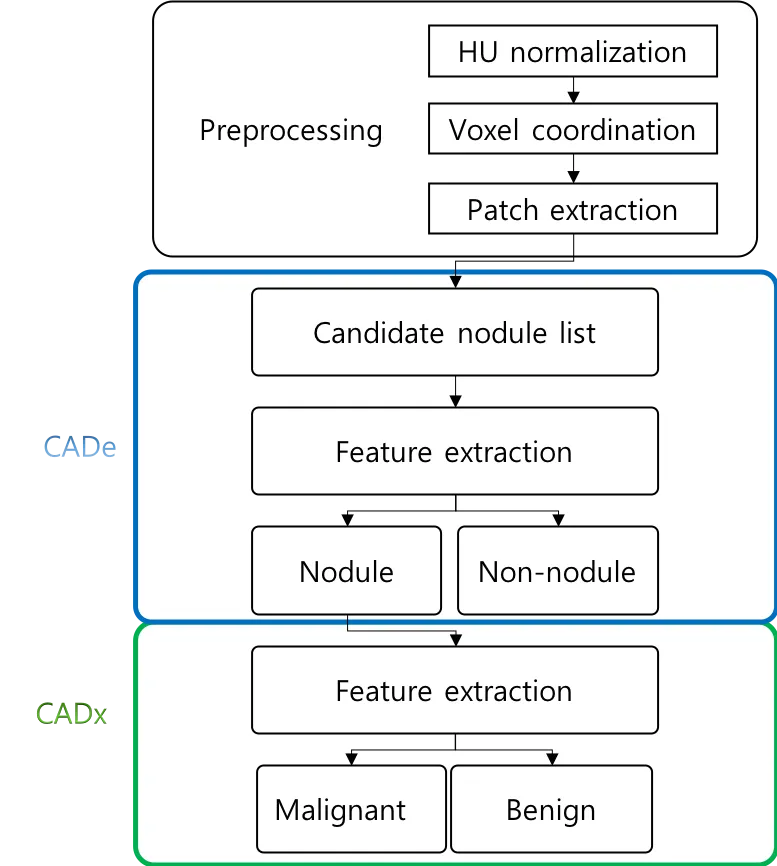
CAD system 을 크게 나누면 detection 과 diagnosis 로 나눌 수 있다.
우리가 시스템에서 원하는 최종 목적은 결국 병변을 검출하고(detection) 그 병변이 실제로 얼마나 심각한 병인지를(diagnosis) 알기 위함이다.
따라서, 전체 process 를 나열하면 위의 그림과 같다고 할 수 있을 것이다.
이중, preprocess 는 이전 포스트에서 코드와 함께 확인 할 수 있다.
사실 CT 영상은 preprocess 가 간편한 편이다. MRI 영상의 경우 복잡한 뇌영상을 사용하기 위해 복잡한 preprocess 를 거쳐야 한다.
MRI 에 대해서는 다른 글을 통해 좀더 정리하도록 하겠다.
우선 CT 영상에 집중을 하자면, preprocess 가 끝나면 우리는 candidate nodule patches 를 얻을 수 있게 된다.
이 patch 가 포함하고 있는 영역과 label 및 loss function 에 따라 학습되는 모델의 의미가 정해지게 된다.
LUNA16 dataset 의 경우 제공하는 데이터와 label 은 GT 결절의 중심 위치와
그 중심을 기준으로 x, y, z 축의 크기를 지정한 영역의 patch를 획득 가능하다.
따라서, 우리의 모델은 candidate nodule 과 그 일정 주변 영역에 대한 label을 확보 가능하다.
즉, Patch 의 크기는 모델이 결절을 분류하기 위해 얼마만큼의 정보를 필요로 하게 되는지를 정하는 중요한 요소이다.
[Dou et al., IEEETMI, 2017] 이 논문은 LUNA16 데이터셋을 다루는 모든 학생들이 반드시 읽어야 하는 논문이라고 생각한다.
왜냐면, LUNA16 데이터셋의 모든 nodule 을 직접 counting 하면서 그 크기에 대해 정리한 논문이기 때문이다.
이 부분이 시사하는 바는 2가지이다.
- 결국 nodule 의 patch 크기를 specific 하게 정하기 위해서는 결국 모든 결절을 확인해 봐야 한다는 점이고,
- 사실 이 두번째가 더 큰 내용이라고 생각하는데, LUNA 데이터셋이 너무 많이 연구된 데이터 셋이라는 점이다.
두번째 이유는 논문을 쓸때 고려해야 하는 부분이라고 생각되는데, 그렇지 않고 실험적으로 사용하기에는
쉽게 접근할 수 있다는 점에서 데이터 셋의 의의가 있다고 하겠다.
이처럼 결절의 주변 영역을 포함한 patch 를 사용해 non-nodule 을 분류 하고 나면,
이제 nodule 과 그 EMR 데이터를 통해 malignant and benign 을 분류 해야한다.
다음 부터 작성하는 [study] CAD 시리즈 글에서는 그동안 읽은 논문들을 정리하면서 CNN 의 등장이 어떠한 영향을 미쳤는지,
확인해보고 최신 ML 알고리즘이 적용된 CAD 시스템을 확인해보고자 한다.
한가지 미리 언급하자면, 이글에서는 CNN 의 기본 개념이나 그 수식 같은 내용은 전혀 다루지 않을 것이다.
결론부터 말하자면, 결국 CNN 은 feature extractor 의 역할을 대신하는 것으로 사용되고있다.
CNN 의 hierarchical 한 성질과 그 convolution kernel 의 sliding window 방식으로 영상의 특징을 추출한다는 점이,
기존의 feature extraction algorithm 과는 다른 specific 한 정보만을 추출하지 않고
다양한 morphological feature 를 추출할 수 있다는 점이 최근 CNN 을 사용하는 장점이 된다.
오늘은 여기까지, 다음에는 Related works paper 들과 함께 간략히 내용을 정리해 보도록 하겠다.