Some interesting snippets of an email I wrote to a colleague today to try to explain how snapshots work on the IBM:
Copy-on-write: 1 read and 2 writes. “Almost instantaneous” and “highly space efficient” but impacts performance on the original volume because write request to the orig. volume must wait while the orig. data is being “copied out” to the snapshot.
IBM FlashCopy® (NOCOPY), AIX® JFS2 snapshot, IBM TotalStorage® SAN File System snapshot, IBM General Parallel FIle System snapshot, Linux® Logical Volume Manager, and IBM Tivoli Storage Manager Logical Volume Snapshot Agent (LVSA) are all based on copy-on-write.
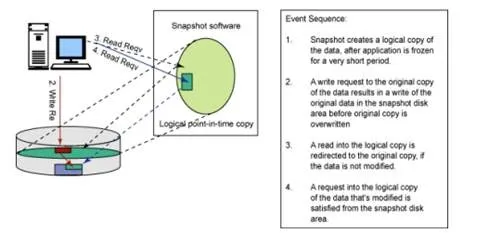
Redirect-on-write: 1 read and 1 write. Although you save the performance hit by eliminating one of the writes- When a snapshot is deleted, the data from the snapshot storage must be reconciled back into the original volume. Also, the snapshot relies on the original copy of the data and the original data set can quickly become fragmented.
IBM N series and the NetApp Filer snapshot implementation is based on redirect-on-write.
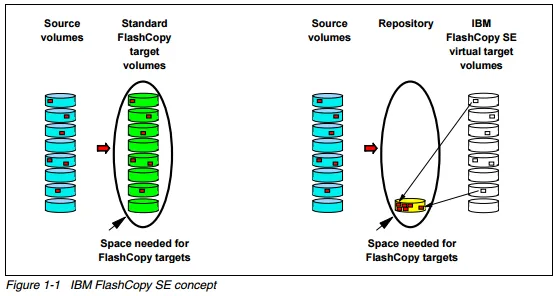
“IBM FlashCopy SE uses space efficient volumes as FlashCopy target volumes. A space efficient volume has a virtual size that is equal to the source volume size. However, space is not allocated for this volume at the beginning when the volume is created and the FlashCopy is initiated; instead, space is allocated in the repository when a first update is made to original tracks on the source volumes and those tracks are copied to the FlashCopy SE target volume. Writes to the SE target also consume repository space.”
Sources:
“Understanding and exploiting snapshot technology for data protection, Part 1: Snapshot technology overview” https://www.ibm.com/developerworks/tivoli/library/t-snaptsm1/index.html
“IBM System Storage DS8000 Series: IBM FlashCopy SE” http://www.redbooks.ibm.com/redpapers/pdfs/redp4368.pdf