Almost every new technology that lets you wonder how do they know that or do this deploy deep learning algorithms — the secret sauce of artificial intelligence.
Among many ... many other things, here is a short and sweet list of some impressive tasks that deep learning accomplishes or contributes to.
- translate between languages
- recognise emotions in speech and faces
- drive
- speak
- spot cancer in tissue slides better than human epidemiologists
- sort cucumbers
- predict social unrest 5 days before it happens (highly interesting; read more about it here)
- trade stocks
- predict outcomes of cases of European Court of Human Rights with ~80% accuracy (read)
- beat 75% of Americans in visual intelligence tests (read)
- beat the best human players in pretty much every game
- paint a pretty good van Gogh (read)
- play soccer badly (read)
- write its own machine learning software (read)
As artificial intelligence is already very advanced in a lot of tasks, it is still at the beginning and thus an understandable technology that is not too late to learn yet.
If you would like to have a basic understanding of how deep learning works in general, I recommend you to read this very blog post series. This post is the second piece of that series.
To read the first introductory part, click here.

Generally — Deep learning (DL) is a field of artificial intelligence (AI) that uses several processing steps, aka layers, to learn and subsequently recognize patterns in data. These methods have dramatically improved the state of the art in speech recognition, visual object recognition, and many other domains.
3. Deep Learning Convolutional Neural Networks
DL architectures that are called convolutional neural networks (CNNs) are especially interesting because they have brought about breakthroughs in processing video and images. And, in the same time, they are relatively straight forward to understand. Their quick off-the-shelf use has been enabled by open source libraries such as TensorFlow or theano.
The founding father of CNNs is Yann LeCun who published them first in 1989, but he had been working with them since 1982. Like every deep neural network, CNNs consist of multiple different layers — the processing steps.
The speciality here is the convolutional layer in which the processing units within a layer work in such a way that they respond to overlapping regions in the visual field. In simple terms, since a convolutional layer processes let's say an image parallelly, it works in an overlapping manner to understand the full image properly.
The processing units are also known as neurons to further nurture the analogy to a human brain.
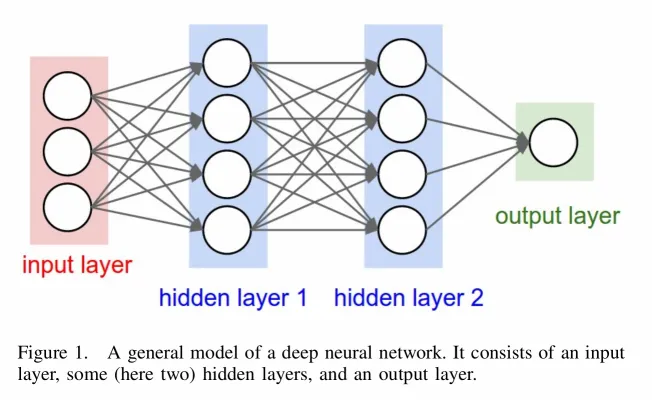
To understand the big picture of a DL architecture, I will not only explain how a convolutional layer works, but also the input layer, a rectifier linear unit layer, a pooling layer, and the output layer.
Later in the blog post series, I go beyond theory and build a CNN using the open source software TensorFlow to run the CIFAR-10 benchmark. It consists of 60 000 images and requires them to be classified correctly at the end.
Some examples how the CIFAR-10 dataset looks like:

We will see later how the deep learning network learns by using a simple method called gradient descent. In AI it is possible to measure how well or bad a network learned and we as well will see how the loss per every learned bit gradually decreases. The loss tells us how wrong the network currently is.
A. Input Layer
The nodes of the input layer are passive, meaning they do not modify the data. They receive a single value on their input, and duplicate the value to their multiple outputs which are the inputs of the following layer.
To better describe what values the input layer propagates, let's take a closer look at an image input. For example, if we take an image of a black four on white background, then one possible way to interpret its values could be that the processing units translate the input values into values from −1 to +1. While white pixels are then denoted by −1, black pixels would denote +1 and all other values, like transitions between black and white regions, hold values between −1 and +1.

Since the objects' shape carries the most crucial information, that is to say what number it is, transitional values between black and white are most interesting in this case. A CNN would deduce a model from the training data that tries to understand the objects' shape.
It would be very complex to develop an algorithm that takes all observable pixel values deterministically into account. Numbers, especially when hand-written, can be tilted, stretched and compressed.
NEXT PART: CNNs and its remaining layers - simplified explanation.
I thrive to write quality blog posts here on steemit to really add value to this amazing platform (and to further push paradigm shift due to the blockchain). I hope this format was good for you. If not, leave me a comment and I will work on it.
Further questions? Ask!
I am working on follow-up blog posts, so, stay tuned!
If you liked it so far, then like, resteem and follow me: @martinmusiol !
Thank you!