Details
Here is a litle homework in data science with python, the job is described in the assignment-data-science.pdf , create a hash table (dictionary) of the number of unique words in a HTML doc, this time in a .txt file , this HTML doc is divided by "articles", there are 3 "articles" where the job is to filter the unique words in this articles, for example the word
[the] -> [1, 20] -> [2, 34] -> [3, 12]
which represent the presence of the [word] in [article 1: 0 times], in [article 2: 1 times], in [article 3: 56 times].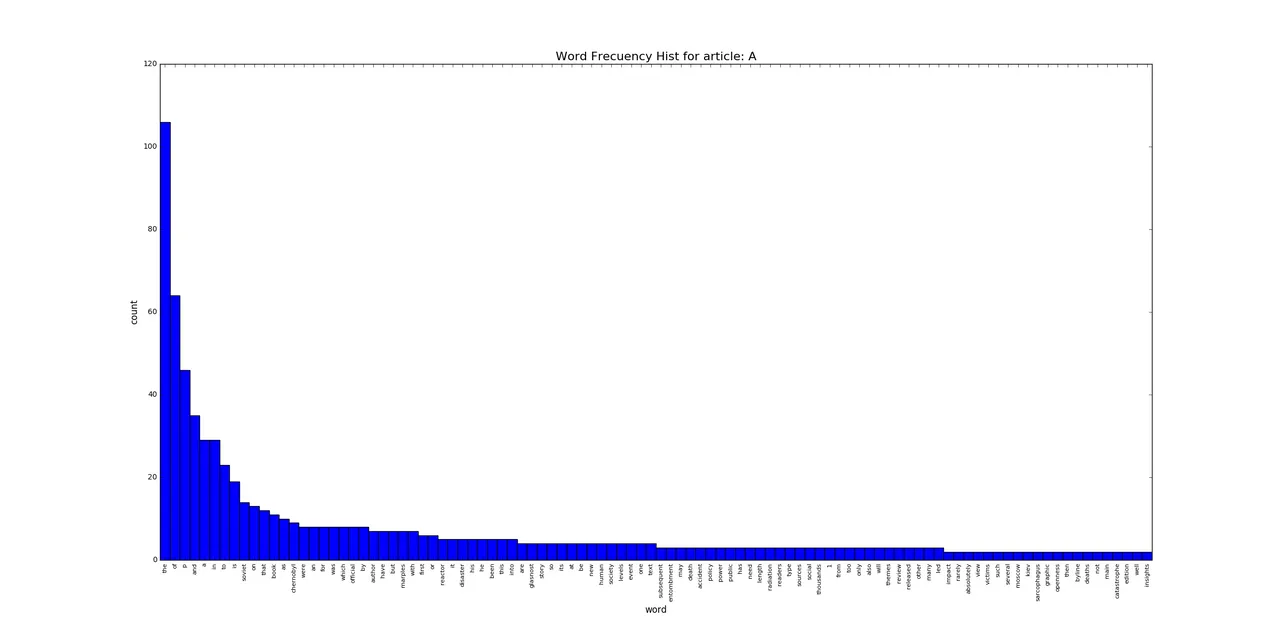
Also the class has a plot method to show the top n word frequency in a given article.
Outline
Scope of Analysis
This code expects a HTML code into a .txt file that conatin the <docno> </docno> tags to filter the information into this tags, still remain the generalization of this tag to any tag .
Tools
I assume that you have a jupyter notebook installed in your Windows or Linux machine.
Python used for this task was 3.5
Results
The results are into the folder /word_counting
For see the code in action just:
$ git clone https://github.com/stanlee321/word_counting
$ cd word_counting
$ python3 code.py
For open the notebook and check the code cells
$ jupyter notebook
and check your localhost and open the
collections_word_counting.ipynb
This is my first time writing this kind of articles, I hope this code helps to someone.
Posted on Utopian.io - Rewarding Open Source Contributors