Repository
https://github.com/superoo7/worldcup
Introduction
In previous post on development update for @blocktrades worldcup competition, I shared about the task, I was being assigned to work on. It is basically a data extraction from more than 2000 posts on steem blockchain, in order to know who are final winners of the competition.

I decided to setup this repo just for reference of data: https://github.com/superoo7/worldcup
Outline
- Scope
- Summary
- Data Extraction
- Data Visualization
- Possible of errors
- Conclusion
- Tools and Scripts
- Relevant Links and Resources
Scope
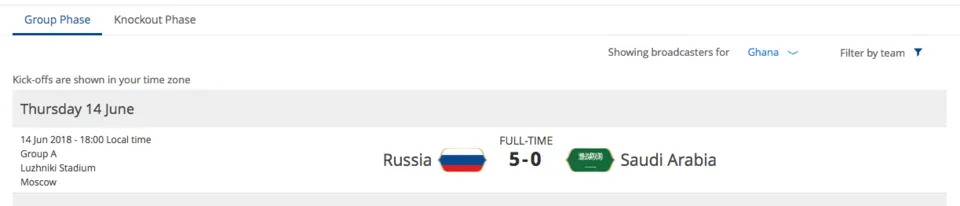
Time in Ghana which is GMT+0, is where the first match of FIFA 2018
The data is extracted out on 16th June 2018, where the timeframe is before 14/06/2018 6pm GMT+0, just before the first match of FIFA 2018.
Results
Summary
There are 2481 total posts being posted for this competition, where you need to fulfill a few rules:
- Last edit before 14/06/2018 6pm GMT+0.
- Reputation > 35.
- Use the tag of #blocktradesworldcup and #mypicks.
- Only submission in English.
- Follow the templates given, using w, l, t to indicates the winning condition.
- If invalid logic of conditions is received (2 winning team), the choice will be considered as n/a.
After the filter, there are 1815 posts left, which will be used in this analysis.
Data Extraction
The data extraction process are as followed:
- Check reputation of the authors.
- Check whether an author make multiple posts
- Extract out data by using string replacement and regex
- Data Visualization
Script written in TypeScript to extract data out with Regex and string replacement.
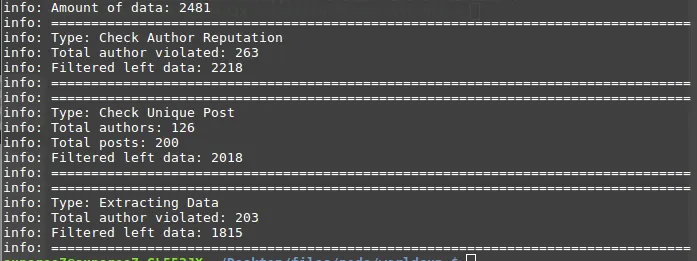
Based on SteemSQL, there are 2481 posts for the entry of competition, which is checked by using the tag #blocktradesworldcup and #mypicks.
After the first level of filter on reputation of the author (reputation > 35), they are 263 violated users, which made the amount of posts reduce to 2218.
Then, the script check whether an author made multiple posts, these will be check later on maybe by manually or a script, to add in the user's data into the existing one. This reduce the amount of posts to 2018.
Lastly, the data are being extracted into w (win), l (lose), t (tie), o (n/a), which it indicates the Left Hand Side (LHS) as a parameter. In Russia VS Saudi Arabia wise, w indicates Russia win; l indicates that Saudi Arabia wins. In addition, the script also manage to extract data out from HTML table and Markdown Table.
Data Visualize
By using Tableau for data visualization, I am able to build a few plotted data out.
Combination of choices
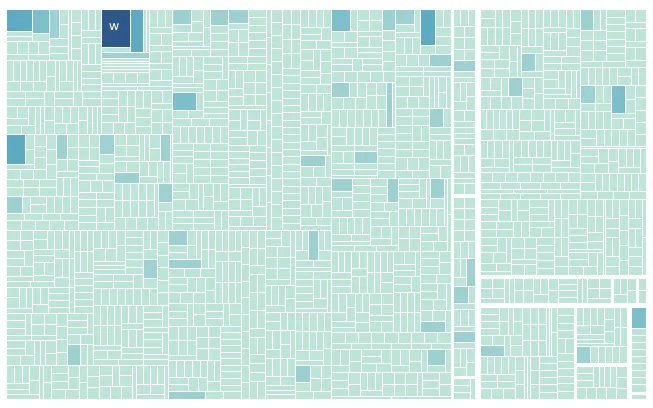
The amout of combinations of choices made by all authors
Although we expect this to be unique (since everyone would make different choices), but there still a small group of people chose the same condition out from 48 matches.
Choices made
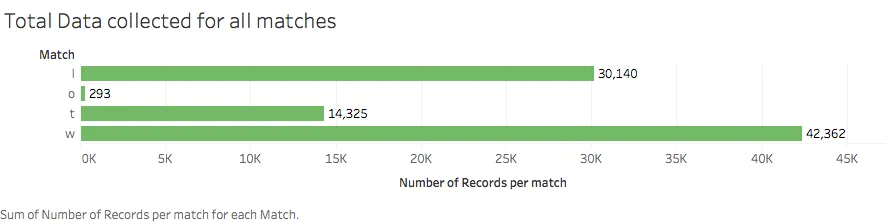
Based on the data collected, there are 87,120 (1815*48) conditions where 293 of them are invalid, due to invalid winning conditions (2 winning team or 2 losing team), etc, which contributed to 0.3363% to the total amount of choices.
Compiled of all data
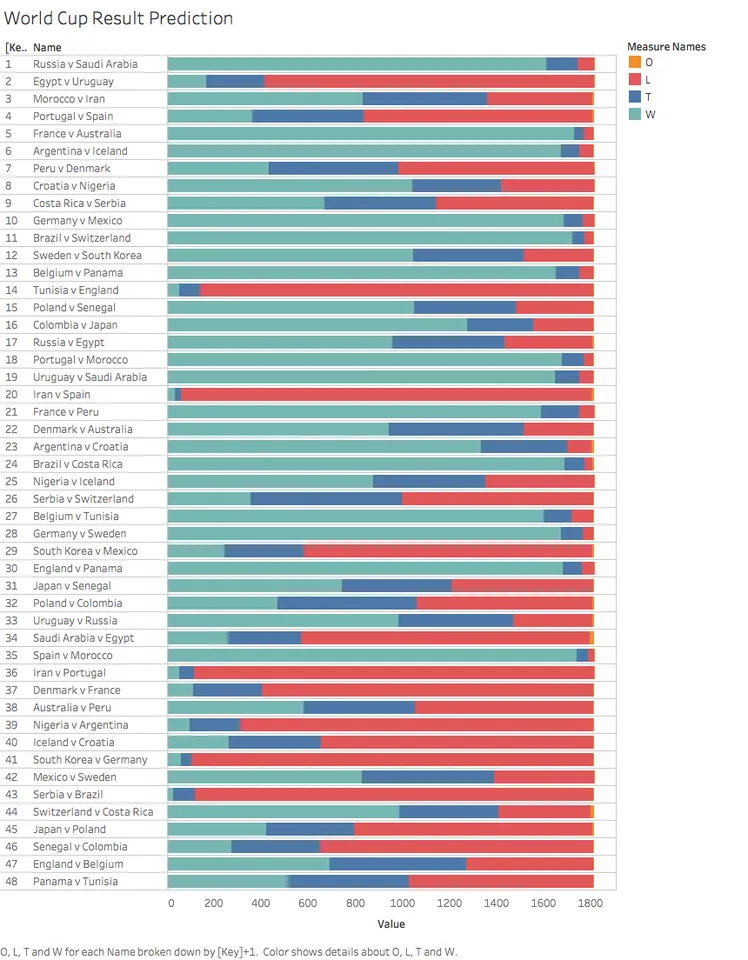
This is the total compiled version of user's choice behavior. The green color indicates the LHS as the winner, the blue color indicates a draw, red color indicates LHS as the loser and RHS as the winner, and orange indicates invalid data.
Let's just take a few played matches as examples for analysis.
Russia VS Saudi Arabia (W)
Russia won this game, which shows the majority have picked the correct choices.Egypt VS Uruguay (L)
Uruguay won this game, the majority also picked Uruguay as their choice.Morocco VS Iran (L)
Iran won this game but the majority picked Morocco to win.Portugal VS Spain (T)
This match is a draw, but based on the choices, Spain are more favourable.Frace VS Australia (W)
France won this game, which also shows the majority have picked the correct choices.Argentina VS Iceland (T)
This is another game that is a tie, but the majority have picked Argentina.
If you interested in a more in-depth analysis of each matches (7 days ago's post), you can check out @petermail 's post
Possible of errors
- There are still 200 posts to be reviewed due to duplications, I will be working on that manually or by script.
- I had been added a lot of testing into Jest, a testing framework for creating this analysis, which I think that my script had covered most cases (including
<table>HTML table instead of MarkDown table) - In some cases, authors does not following templates given, using their own version, Win instead of W; or changed the country name into non-English, and wrong spelling of Country (English instead of England).
- The script also only accept the country being sorted in the order given in the template.
Conclusion
I am glad that I was being assigned to carry out this task, just wait a few more days until World Cup group stage is over, and we can know who are the winners!
I would suggest the contest holder create a simple template for users to share their result, to prevent confusion and such a complex extraction need to be carried out. The project is open source but required you to have a SteemSQL subscription in order to use it. If you don't have SteemSQL subscription, maybe you can try out the json file in the repository for data analysis.
Tools and Scripts
- SteemSQL - Extracting data
- TypeScript - To run data extraction with Regex and string replacement
- Jest - To test individual functions created for data extraction
- Tableau - Data visualize tools
Relevant Links and Resources
SQL Query for extracting data
SELECT
Comments.author,
Accounts.reputation,
Comments.permlink,
Comments.json_metadata,
Comments.created,
Comments.last_update,
'https://steemit.com/' + Comments.parent_permlink + '/@' + Comments.author + '/' + Comments.permlink as url,
Comments.body
FROM Comments
LEFT JOIN Accounts ON Comments.author = Accounts.name
WHERE
Comments.depth = '0' AND
CONTAINS(Comments.json_metadata, 'blocktradesworldcup') AND
CONTAINS(Comments.json_metadata, 'mypicks') AND
Comments.created < '2018-06-14 18:00:00' AND
Comments.last_update < '2018-06-14 18:00:00'