Many would call it a portfolio tracker, not a snapshot tool... And maybe that's what it is, except a focused one on certain assets. I preferred to use the term "snapshot" because that's the main use case I thought for it initially.
I presented the first version of the script a few days ago here. Since then, I had a few iterations I haven't made public until now.
Shortly after publishing my script during the week, I discovered it has quite a poor error handling which becomes obvious when someone tried it with more than a few tokens.
This wasn't as easy to fix as one may think (for me... or for the AIs). In fact, it took the majority of my time working on it since then. I only fixed it completely (hopefully) this morning.
It's also interesting that the more I work with different AI models, I discover which is good for what, and I also started to come across the issues of hitting each model's max length response for certain prompts (one in particular), which wasn't easy to work around, but eventually I did.
Since I had more time, I decided to work on adding diesel pools to the snapshot report, which I did. The script lists ALL diesel pool positions the account has, no need to specify any one in particular, and also shows an aggregate situation across the holdings corresponding to the list of tokens and all the diesel pools.
Also, tokens with zero holdings are not shown, to condense the information.
Here's a screenshot with one of my final tests:
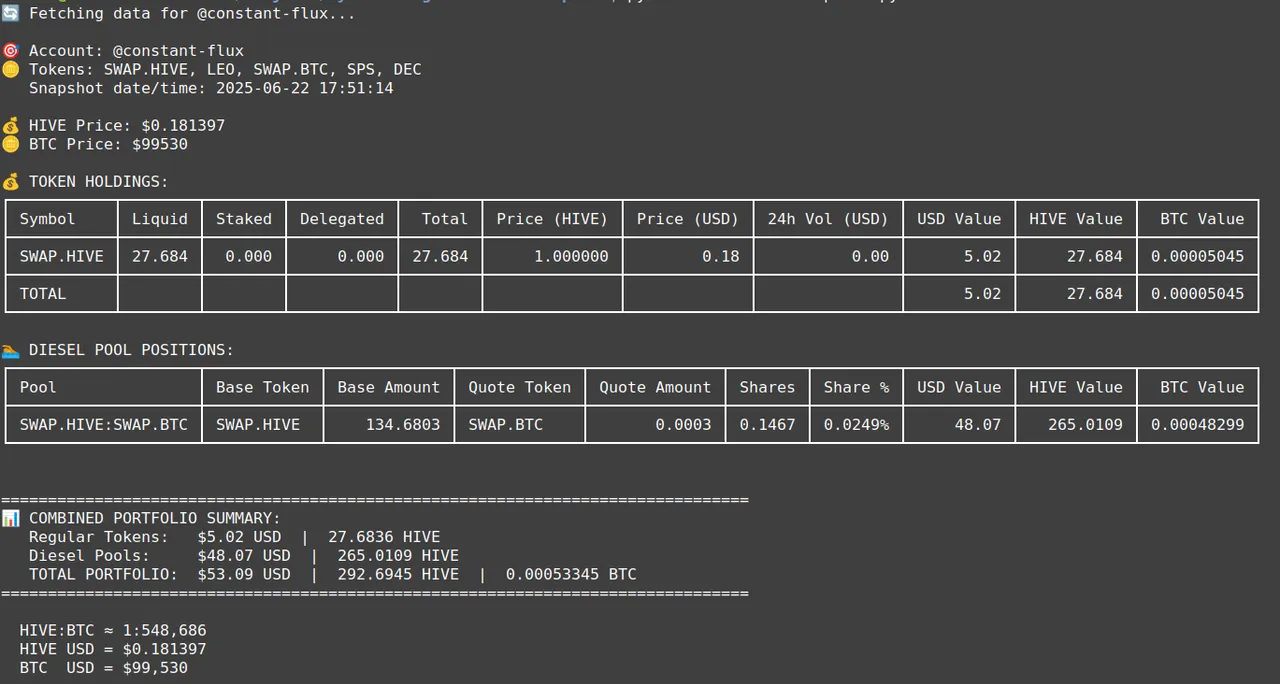
You can find the Hive Engine Snapshot tool here, but you need to know how to run Python scripts to make it work. You can ask an AI if you don't, by the way...
We'll see what comes next. I have more ideas but let's see if I have the determination to push it to a higher level. If you have questions or want to share your impressions/advice, etc. I'd appreciate them.