There has been some discussion about AI and LLM generated content on HIVE. The overall consensus appears to be that LLM and AI content is bad, but I have yet to see any conclusive, wide spread analysis of the recent content on HIVE.

An unironic,AI / LLM generated image as a headline picture
There are websites like GPT-Zero that are able to "detect" if something is written using AI, using some sort of probability analysis. Tools like GPT Zero are closed source, paid, and subscription only, and as one human, I am unlikely to reach the level of sophistication that their models use. Firstly, I'm not a linguist, and I am also not an expert sys admin, software engineer, or developer.
I have the ability to run several Local LLMs on my machine, and figured I would experiment, using hive content to try and detect the likelihood of content on HIVE having been written by a LLM.
I am a single man with a casual interest in these things, and the ability to write some Python to hook into other software tools that I have access to.
I started by installing LM Studio, and downloaded a few different models. There is not much recent information published online about the best models for detection, particularly with the advent of many hundreds of models, fine tunes, and the sheer numbers of text generators that now exist on the Internet.
As a result, I experimented with a few models. I got a Python script to hook into LM Studio's local API (as in, a server running on my computer) - and fed it the prompt:
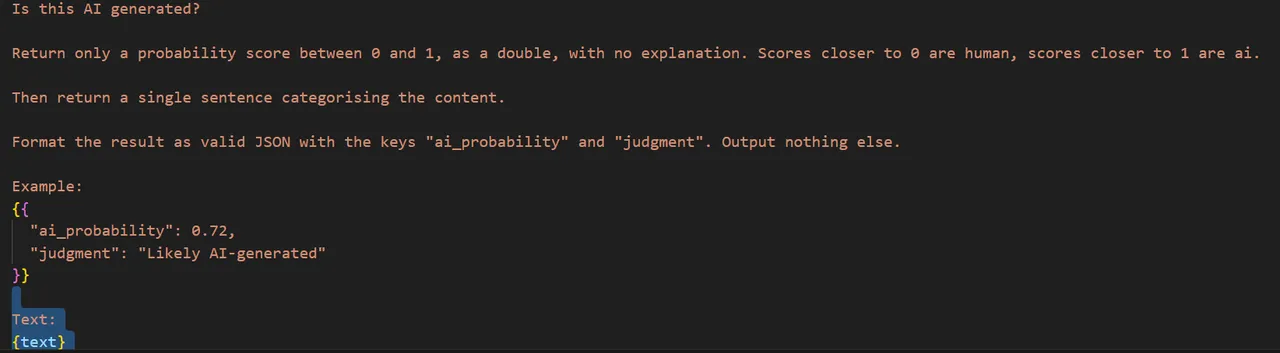
Given that the samples I fed this are the same used for my weekly analysis on post length, I have a file with something like 50,000 HIVE posts stored locally on my machine. I got the script to feed 100 randomly sampled examples into the LLM, and for it to give me a score.
The console output was something like this:
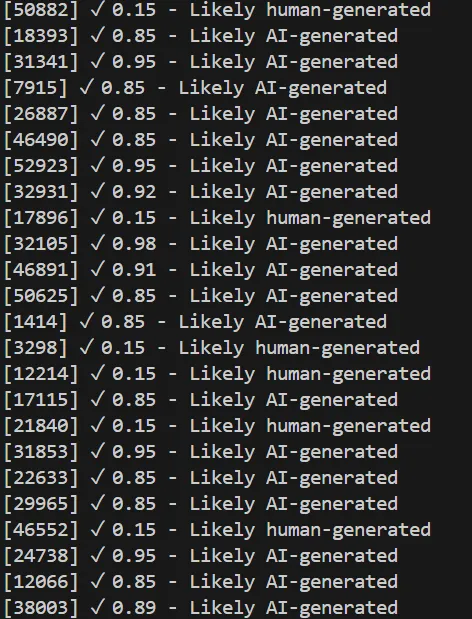
This shows the row number, the probability and a judgement.
Once 100 results are completed, the script does some mathematics to normalise the 100 random samples to the whole data set.

Based on the 100 samples that the script randomly selected:

I am fairly certain that human written content on HIVE comprises of more than 63%, but I could be wrong. The issue here is the volume of posts, the volume of text, and the computational resources available to assess this.
I then went and looked through the 100 randomly sampled rows, and there were some interesting findings:
- The AI categorised some human written content (albeit with low levels of mastery of the English language) as AI, instead of human
- The 100 samples contained many generated posts by various known bots, indicating that the data must first be cleaned further before analysis
- There are posts in languages other than English that become sampled, it is unclear if the LLM is taking into account other languages when completing its probalistic analysis
- It could all be a massive hallucinated result, not grounded in reality.
There are also questions as to the ability of one LLM to detect output of another LLM.
So, I encourage people to use their eyes, their brains, their hands, their corporeal appendages, and their thoughts to examine content on HIVE closely, and ask "Does this seem to enter the uncanny valley of LLM output?"
And if you think that it does - call the author out on it. They may be using a translation service, or they may have tried to mask AI writing in their post.
If you call them out and they change their habits - GOOD. If you call them out and there is no response - then you have a choice to accept that content, or to do something about it.
People who care about their own integrity and the integrity of the platform itself will change their habits. If they don't - then, are they the sort of people we want on HIVE anyway?
Disclosure: some of the scripts used for this post (not shared at this time) were generated using LLM in the interest of bringing this analytical process to life far quicker than I could have using my own coding "skills" alone.
The full code, if anyone is interested:
import requests
import json
import random
import time
import re
CSV_INPUT = "Concat.csv"
CSV_OUTPUT = "sampled_ai_analysis.csv"
TEXT_COLUMN = "body trim clean"
AUTHOR_COLUMN = "author"
LM_API_URL = "http://localhost:1234/v1/chat/completions"
MODEL_NAME = "qwen/qwen3-8b"
SAMPLE_SIZE = 100
MAX_TEXT_LENGTH = 2000
# Attempt to load the CSV with fallback encodings
encodings = ['utf-8', 'ISO-8859-1', 'utf-16']
for enc in encodings:
try:
df = pd.read_csv(CSV_INPUT, encoding=enc)
break
except UnicodeDecodeError:
continue
else:
raise ValueError("Could not read the CSV file using standard encodings.")
# Check required columns
if TEXT_COLUMN not in df.columns or AUTHOR_COLUMN not in df.columns:
raise ValueError(f"Required column(s) not found: '{TEXT_COLUMN}' and/or '{AUTHOR_COLUMN}'.")
# Sample 100 random rows
sampled_df = df.sample(n=min(SAMPLE_SIZE, len(df)), random_state=42).copy()
# Helper to extract JSON content
def extract_json(text):
match = re.search(r'\{.*?\}', text, re.DOTALL)
if match:
try:
return json.loads(match.group())
except json.JSONDecodeError:
return None
return None
# Create the prompt
def make_prompt(text):
return f"""
Is this AI generated?
Return only a probability score between 0 and 1, as a double, with no explanation. Scores closer to 0 are human, scores closer to 1 are ai.
Then return a single sentence categorising the content.
Format the result as valid JSON with the keys "ai_probability" and "judgment". Output nothing else.
Example:
{{
"ai_probability": 0.72,
"judgment": "Likely AI-generated"
}}
Text:
{text}
"""
# Output containers
probabilities = []
judgments = []
texts = []
authors = []
# Process each sampled row
for idx, row in sampled_df.iterrows():
text = str(row[TEXT_COLUMN])[:MAX_TEXT_LENGTH]
author = row[AUTHOR_COLUMN]
messages = [
{"role": "system", "content": "Respond only with valid JSON, do not explain."},
{"role": "user", "content": make_prompt(text)}
]
payload = {
"model": MODEL_NAME,
"messages": messages,
"temperature": 0.2,
"max_tokens": 100
}
try:
response = requests.post(LM_API_URL, json=payload, timeout=30)
response.raise_for_status()
content = response.json()["choices"][0]["message"]["content"]
parsed = extract_json(content)
if parsed and "ai_probability" in parsed and "judgment" in parsed:
probabilities.append(parsed["ai_probability"])
judgments.append(parsed["judgment"])
else:
probabilities.append(None)
judgments.append("Could not parse")
texts.append(text)
authors.append(author)
print(f"[{idx}] ✓ {parsed['ai_probability'] if parsed else 'N/A'} - {parsed['judgment'] if parsed else 'Parsing failed'}")
except Exception as e:
probabilities.append(None)
judgments.append(f"Error: {e}")
texts.append(text)
authors.append(author)
print(f"[{idx}] Error: {e}")
time.sleep(0.5) # throttle
# Create final DataFrame
output_df = pd.DataFrame({
"author": authors,
"body": texts,
"ai_probability": probabilities,
"judgment": judgments
})
# Save the sample analysis
output_df.to_csv(CSV_OUTPUT, index=False, encoding='utf-8')
print(f"\nSample analysis saved to: {CSV_OUTPUT}")
# Compute average AI probability across the sample
valid_probs = [p for p in probabilities if isinstance(p, (int, float))]
if valid_probs:
average_prob = sum(valid_probs) / len(valid_probs)
estimated_total_ai_percent = average_prob * 100
print(f"\n Estimated AI-generated rate (sampled): {estimated_total_ai_percent:.2f}%")
print(f"Extrapolated from sample of {len(valid_probs)} out of {len(df)} total rows")
else:
print("No valid probability scores returned to estimate AI proportion.")